Is there any way we confirm it's using cloud fetch?
I'm not sure what's the exact size, but it's up to 100s of GB of data across multiple queries.
Looking at the metrics from the VM that's executing the query, the max throughput is 60MBps
It doesn't seem to match the throughput seen in the document. It's closer to the Baseline with single threaded. I'm using 2.6.19 ODBC driver
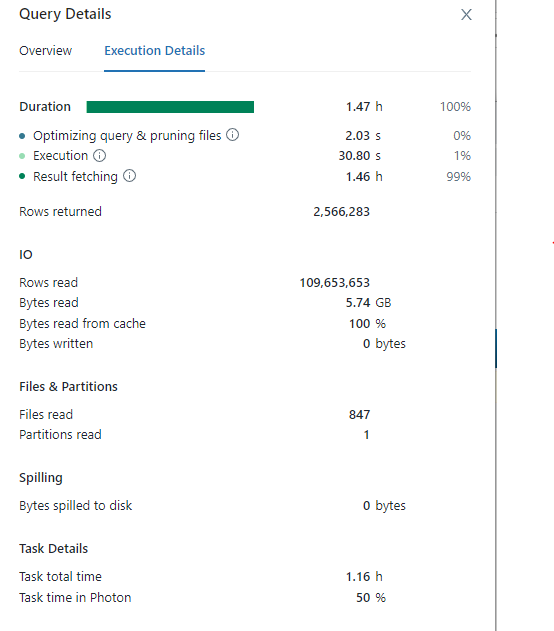
Here's sample execution details for one query








{kind=link}