Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- How to efficiently process a 100GiB JSON nested fi...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to efficiently process a 100GiB JSON nested file and store it in Delta?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-07-2022 04:22 AM
Hi, I'm a fairly new user and I am using Azure Databricks to process a ~1000GiB JSON nested file containing insurance policy data. I uploaded the JSON file to Azure Data Lake Gen2 storage and read the JSON file into a dataframe.
df=spark.read.option("multiline","true").json('mnt/mount/Anthem/2022-10-11/IndexFile/2022-10-01_anthem_index.json.gz')This reading of JSON file is taking ~25 minutes for a 33GiB file.
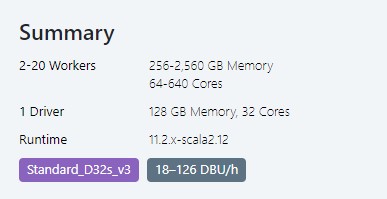
My Cluster Configuration Summary:

root
|-- reporting_entity_name: string (nullable = true)
|-- reporting_entity_type: string (nullable = true)
|-- reporting_structure: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- allowed_amount_files: struct (nullable = true)
| | | |-- description: string (nullable = true)
| | | |-- location: string (nullable = true)
| | |-- in_network_files: array (nullable = true)
| | | |-- element: struct (containsNull = true)
| | | | |-- description: string (nullable = true)
| | | | |-- location: string (nullable = true)
| | |-- reporting_plans: array (nullable = true)
| | | |-- element: struct (containsNull = true)
| | | | |-- plan_id: string (nullable = true)
| | | | |-- plan_id_type: string (nullable = true)
| | | | |-- plan_market_type: string (nullable = true)
| | | | |-- plan_name: string (nullable = true)Because the data is a nested JSON file, I have used the following function code to flatten the data.
from pyspark.sql.types import *
from pyspark.sql.functions import *
def flatten(df):
# compute Complex Fields (Lists and Structs) in Schema
complex_fields = dict([(field.name, field.dataType)
for field in df.schema.fields
if type(field.dataType) == ArrayType or type(field.dataType) == StructType])
while len(complex_fields)!=0:
col_name=list(complex_fields.keys())[0]
print ("Processing :"+col_name+" Type : "+str(type(complex_fields[col_name])))
# if StructType then convert all sub element to columns.
# i.e. flatten structs
if (type(complex_fields[col_name]) == StructType):
expanded = [col(col_name+'.'+k).alias(col_name+'_'+k) for k in [ n.name for n in complex_fields[col_name]]]
df=df.select("*", *expanded).drop(col_name)
# if ArrayType then add the Array Elements as Rows using the explode function
# i.e. explode Arrays
elif (type(complex_fields[col_name]) == ArrayType):
df=df.withColumn(col_name,explode_outer(col_name))
# recompute remaining Complex Fields in Schema
complex_fields = dict([(field.name, field.dataType)
for field in df.schema.fields
if type(field.dataType) == ArrayType or type(field.dataType) == StructType])
return dfCalling the flatten function
df_flatten = flatten(df)This gives the output as follows
Processing :reporting_structure Type : <class 'pyspark.sql.types.ArrayType'>
Processing :reporting_structure Type : <class 'pyspark.sql.types.StructType'>
Processing :reporting_structure_allowed_amount_files Type : <class 'pyspark.sql.types.StructType'>
Processing :reporting_structure_in_network_files Type : <class 'pyspark.sql.types.ArrayType'>
Processing :reporting_structure_in_network_files Type : <class 'pyspark.sql.types.StructType'>
Processing :reporting_structure_reporting_plans Type : <class 'pyspark.sql.types.ArrayType'>
Processing :reporting_structure_reporting_plans Type : <class 'pyspark.sql.types.StructType'>I then tried to display the flattened dataframe df_flatten
df_flatten.display()This gives the following error after ~50 minutes of execution
FileReadException: Error while reading file mnt/monut/mnt/mount/Anthem/2022-10-11/IndexFile/2022-10-01_anthem_index.json.gz
Caused by: OutOfMemoryError: GC overhead limit exceeded
df.write.mode('overwrite').format('delta').save('mnt/monut/mnt/mount/Anthem/2022-10-11/processed/')
Labels:
- Labels:
-
Apache spark
-
Azure
-
Nested json


3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-07-2022 05:37 AM
Do you have access to the data at source? See if you can pull the data down into storage in pieces instead of it being such a huge single file.
If you have a single JSON file, everything will be allocated to a single core and the decompression is just going to nuke your executor memory - hence the garbage collector not being able to free up space and dying eventually. It won't really matter how big the cluster is either with such a file. Will need to chop that file up into chunks before feeding to spark so the entire cluster can take a small chunk of it and process in parallel.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-07-2022 05:41 AM
Hi @Sameer Khalid ,
check this notebook on how to work with nested json : https://learn.microsoft.com/en-us/azure/databricks/kb/_static/notebooks/scala/nested-json-to-datafra...
what you need to look at is how to work with:
- Struct - col_name.*
- arrays - explode
I might be able to look more closely to the logic of the flatten function later.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-31-2023 08:20 AM
Hi Sameer, please refer to following documents on how to work with nested json:
https://docs.databricks.com/optimizations/semi-structured.html
Announcements





{kind=link}
{kind=link}
Related Content
- Best pattern for ingesting data from hundreds of separate ADLS Gen2 containers into Databricks? in Data Engineering
- Spark structured streaming- calculate signal, help required! 🙏 in Data Engineering
- how to speed up inference? in Machine Learning
- Delta Sharing - Open, Secure, and Barrier-Free Data & AI Collaboration in Data Governance
- Serverless Compute - Spark - Jobs failing with Max iterations (1000) reached for batch Resolution in Data Engineering