Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Pyspark serialization
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Pyspark serialization
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2024 04:50 AM
Hi,
I was looking for comprehensive documentation on implementing serialization in pyspark, most of the places I have seen is all about serialization with scala. Could you point out where I can get a detailed explanation on it?


5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2024 12:37 AM
This is awesome. Thank you for replying.
I want to ask one more thing before we close this, in Scala-spark java serialization is default and additionally we have kryo serialization as well which is better. So these are not applicable in pyspark if i get correctly. Kindly confirm.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-01-2024 06:06 AM
This is great to know!
Thank you for the explanation.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2024 02:50 AM
This is awesome. Thank you for replying.
I want to ask one more thing before we close this, in Scala-spark java serialization is default and additionally we have kryo serialization as well which is better. So, can we use them in pyspark as well?
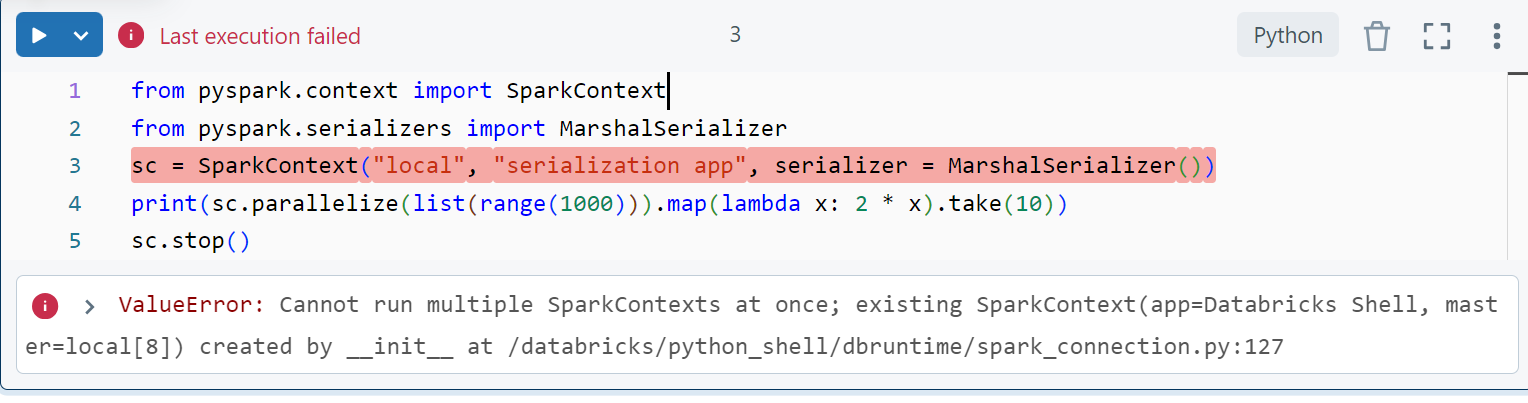
Another important thing, the code below creates a sparkcontext on local, that doesnt work on databricks. When I try to change the sparkcontext arguments, i get an error , attached screenshot, how can we resolve this, ultimately i dont want to run spark locally, but on databricks. Would appreciate if you answer this.
Thanks for the support.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-01-2024 04:27 AM
@Retired_mod Could you clarify on my query? Eagerly awaiting response.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-01-2024 06:05 AM
Thank you @Retired_mod for the prompt reply. This clears the things and also distinguishes between spark-scala and pyspark. Appreciate your explanation. Will apply this and also share any findings based on this which will help the community!
Announcements





{kind=link}
Related Content
- Use of Genie agents for ETL migration in Data Engineering
- Databricks & Microsoft Expand Partnership to 2030s: Architectural Impact on Azure Databricks in Administration & Architecture
- Stop Translating Alteryx Boxes - A Lakebridge-assisted, test-driven migration to Azure Databricks in Data Engineering
- E2E MLOps Part 1: How to build and govern models with AutoML, MLflow, and Unity Catalog in Machine Learning
- StatusCode.UNIMPLEMENTED error: DatabricksConnect library using AKS/PySpark to calling Spark cluster in Data Engineering