For some reason spark is not reading the data correctly from xlsx file in the column with a formula. I am reading it from a blob storage.
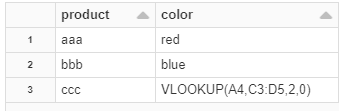
Consider this simple data set

The column "color" has formulas for all the cells like
=VLOOKUP(A4,C3:D5,2,0)
In cases where the formula could not be calculated it is read differently by excel and spark:
excel - #N/A
spark - =VLOOKUP(A4,C3:D5,2,0)
Here is my code:
df= spark.read\
.format("com.crealytics.spark.excel")\
.option("header", "true")\
.load(input_path + input_folder_general + "test1.xlsx")
display(df)
And here is how the above dataset is read:
 How do I get #N/A instead of a formula?
How do I get #N/A instead of a formula?







{kind=link}
{kind=link}