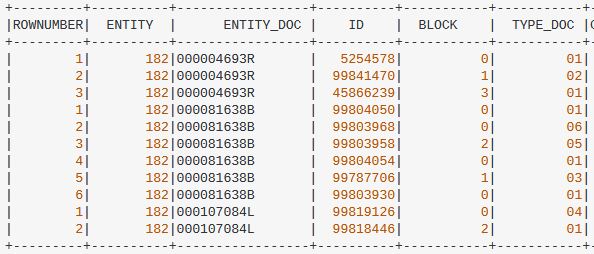
I'm begginner working with Spark SQL in Java API. I have a dataset with duplicate clients grouped by ENTITY and DOCUMENT_ID like this:
.withColumn( "ROWNUMBER", row_number().over(Window.partitionBy("ENTITY", "ENTITY_DOC").orderBy("ID")))
 I added a ROWNUMBER column to know how many clients are there (and I have to compare) for each group. The idea is to evaluate the criteria between the first row and the next, until the group is finished and the best is obtained.It is decided which is the best based on certain business criteria like:
I added a ROWNUMBER column to know how many clients are there (and I have to compare) for each group. The idea is to evaluate the criteria between the first row and the next, until the group is finished and the best is obtained.It is decided which is the best based on certain business criteria like:
//criteria 1 (the best is the ID with BLOCK 0)
BLOCK = 0 or ' ' VS BLOCK 1, 2 or 3
//criteria 2 (the best is the ID with BLOCK 2)
BLOCK = 2 VS BLOCK 1 or 3
//criteria3 (the best is the ID with BLOCK 3)
BLOCK = 3 VS BLOCK 1
//criteria4 (the best is the one with the most recent timestamp)
BLOCKS 1-1 or BLOCKS 3-3
** if BLOCKS 2-2 OR BLOCKS 0-0 evaluate the following criteria
//criteria5 (the best is ID with typedoc 01, 02, 03, 04 or 07
TYPE DOC 01, 02, 03, 04, 07 VS ANY OTHER
//criteria6 (the best is the one with the most recent timestamp)
TYPE DOC 01, 02, 03, 04, 07 VS TYPE DOC 01, 02, 03, 04, 07
Now I have to compare in each group, pairs of rows in order to decide which is the best. This is the big problem, I dont know if its better create an array struct, a map... I dont know how iterate each row inside the same group. An example:
if entity "182" with entity_doc "000004693R" have 3 matches, we have to compare:
First, ROW(1) -> ID 5254578 against ROW(2) ID -> 99841470.
** ROW(1) would be the best because criteria 1.
Following the order, we have to compare the before best ROW(1) -> ID 5254578 VS ROW(3) ID -> 45866239.
** ROW(1) would be the best because criteria 1.
I tried to group each row of the group in a collect_list but I don't know how to access each element to compare it with the next:
root
|-- ENTITY: string (nullable = true)
|-- ENTITY_DOC: string (nullable = true)
|-- COMBINED_LIST: array (nullable = true)
| |-- element: struct (containsNull = false)
| | |-- ID: string (nullable = true)
| | |-- BLOCK: string (nullable = true)
| | |-- TYPE_DOC: string (nullable = true)
| | |-- AUD_TIMESTAM: timestamp (nullable = true)
Example of first group:
+------+-------------------------+--------------------------------------------------------------------------------------
|ENTITY|ENTITY_DOC |COMBINED_LIST
+------+-------------------------+--------------------------------------------------------------------------------------
|182 | 000004693R | [[5254578,0,01, 2005-07-07 01:03:25.613802], [99841470, 1,02, 2005-07-07 01:03:25.613802], [45866239, 3,01, 2000-01-16 09:07:00]] |
The output would be a TUPLE with the best ID and the others ID's LIKE:
+----------+-----------------+----------+----------+------------+
| ENTITY | ENTITY_DOC | ID1 | ID2 |COD_CRITERIA|
+----------+-----------------+----------+----------+------------+
| 182|000004693R | 5254578| 99841470| 1|
| 182|000004693R | 5254578| 45866239| 1|
Can you help me with Spark? Thanks a lot!







{kind=link}