- 11890 Views
- 2 replies
- 0 kudos
Resolved! Show Existing Header From CSV I External Table
Hello, is there a way to load csv data into an external table without the _c0, _c1 columns showing?
- 11890 Views
- 2 replies
- 0 kudos
- 0 kudos
My question was answered in a separate thread here.
- 0 kudos
- 4840 Views
- 3 replies
- 0 kudos
Resolved! Unable to load csv data with correct header values in External tables
Hello, is there a way to load "CSV" data into an external table without the _c0, _c1 columns showing?I've tried using the options within the sql statement that does not appear to work.Which results in this table


- 4840 Views
- 3 replies
- 0 kudos
- 0 kudos
you need set "USING data_source"https://community.databricks.com/t5/data-engineering/create-external-table-using-multiple-paths-locations/td-p/44042
- 0 kudos
- 2196 Views
- 1 replies
- 0 kudos
What is the REST API payload for "not sending alert when alert is back to normal"?
Greeting,I am using REST API to create & schedule sql alert by default these alerts will send notifications when they are back to normal which I don't want, In the UI I have the option to uncheck the box (shown in the picture) but I can't find any do...

- 2196 Views
- 1 replies
- 0 kudos
- 0 kudos
@Lambda Did you refer this documentation: https://docs.databricks.com/api/workspace/alerts/create
- 0 kudos
- 2351 Views
- 1 replies
- 0 kudos
Spark VCore for Databrick vCPU
Hi Team,What is the equivalent Spark VCore for Databrick vCPU? , like for below example for DS3 v2 , vCPU=4 and RAM = 14.00 GiB, would like to know equivalent Spark VCore for DS3 v2 as in Azure Databricks Pricing | Microsoft AzureRegards,Phanindra
- 2351 Views
- 1 replies
- 0 kudos
- 0 kudos
@Phani1 In Databricks, the vCPU count is equivalent to the number of Spark vCores. This means that if the DS3 v2 instance has 4 vCPU, it would also have 4 Spark vCores. Please note that the Spark VCore count is based on the vCPU count of the underlyi...
- 0 kudos
- 1883 Views
- 1 replies
- 0 kudos
Can't enter 'edit mode' using shortcut
Hi,With the recently added AI Assistant to databricks notebooks, I'm having issues entering the 'edit mode' of a notebook cell. Previously, I could simply press the 'Enter' key in order to do this but this no longer works.Is anyone else having the sa...
- 1883 Views
- 1 replies
- 0 kudos
- 0 kudos
@AtomicBoy99, it seems like the fix is in place. Can you confirm if it is working well now?
- 0 kudos
- 5266 Views
- 2 replies
- 0 kudos
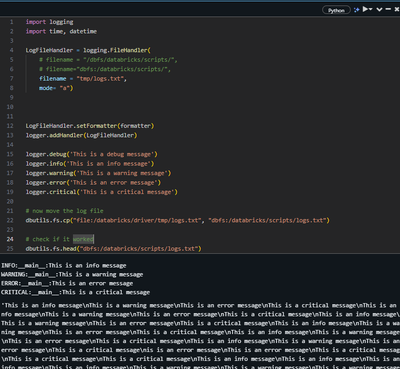
Python Logging cant save log in DBFS
Hi! I am trying to integrate logging into my project. Got the library and logs to work but cant log the file into DBFS directly.Have any of you been able to save and append the log file directly to dbfs? From what i came across online the best way to...
- 5266 Views
- 2 replies
- 0 kudos
- 0 kudos
you can use azure_storage_loggingSet Python Logging to Azure Blob, but Can not Find Log File there - Stack Overflow
- 0 kudos
- 7843 Views
- 2 replies
- 1 kudos
Databricks notebook how to stop truncating numbers when export the query result to csv
I use Databricks notebook to query databases and export / download result to csv. I just accidentally close a pop-up window asking if need to truncate the numbers, I accidentally chose yes and don't ask again. Now all my long digit numbers are trunca...
- 7843 Views
- 2 replies
- 1 kudos
- 1 kudos
@Jasonh202222 - Kindly check the below navigation path user settings -> Account settings -> Display -> Download and Export. Under Download and Export, Enable the checkbox - "Prompt for formatting large numbers when downloading or exporting" and cl...
- 1 kudos
- 8739 Views
- 2 replies
- 1 kudos
Resolved! Difference between username and account_id
I have a web app that can read files from a person's cloud-based drive (e.g., OneDrive, Google Drive, Dropbox). The app gets access to the files using OAuth2. The app only ever has access to the files for that user. Part of the configuration requir...
- 8739 Views
- 2 replies
- 1 kudos
- 1 kudos
The provided links were helpful. The take-away* usernames are "globally" unique to an individual; the username is the person's email.* a username can be associated with up to 50 accounts; account_ids track the resources available to the user.This cl...
- 1 kudos
- 3806 Views
- 0 replies
- 0 kudos
Using streaming data received from Pub/sub topic
I have a notebook in Databricks in which I am streaming a Pub/sub topic. The code for this looks like following-%pip install --upgrade google-cloud-pubsub[pandas] from pyspark.sql import SparkSession authOptions={"clientId" : "123","clientEmail"...
- 3806 Views
- 0 replies
- 0 kudos
- 1120 Views
- 0 replies
- 1 kudos
Error Signing Up for Databricks Community Edition
@Retired_mod I've been trying to sign up for Databricks Community Edition using different email addresses over the past 24 hours, but I keep getting the error message: "An error has occurred. Please try again later." Can anyone help?Tags: #Databricks...
- 1120 Views
- 0 replies
- 1 kudos
- 7084 Views
- 2 replies
- 0 kudos
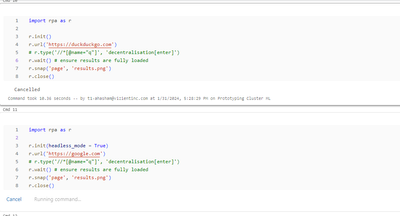
Resolved! Using Python RPA Library on Databricks
Hi I didn't see any conversations regarding using python RPA package on Data bricks clusters. Is anyone doing this or have gotten it to successfully work on the clusters? I ran into the following errors:1) Initially I was getting the error below rega...

- 7084 Views
- 2 replies
- 0 kudos
- 0 kudos
If you want to capture browser screenshot, you can use playwright%sh pip install playwright playwright install sudo apt-get update playwright install-deps from playwright.async_api import async_playwright async with async_playwright() as p: ...
- 0 kudos
- 2834 Views
- 0 replies
- 0 kudos
Unity Catalog: Databricks *Specific* Features
Good day,Deceptively simple question, are there any "Databricks only" specific features that Unity Catalog offers? I understand that generally speaking enabling UC offers some of the following:Data Discovery and LineageAuditing and MonitoringAccess C...
- 2834 Views
- 0 replies
- 0 kudos
- 4339 Views
- 2 replies
- 0 kudos
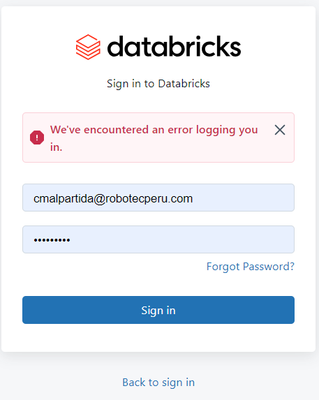
Problem login in
Hello allI´m new in this platform, I sign up, validated my email, create my password everything is fine and when I try to log in and start a message came upI create a new password but same happen again! But it works a few times, I think like 3 times....
- 4339 Views
- 2 replies
- 0 kudos
- 0 kudos
Can you confirm the username was created all lower case? Login is case sensitive so you need to make sure the username is set same exact as you add it in the console or workspace
- 0 kudos
- 3830 Views
- 1 replies
- 0 kudos
how to create volume using databricks cli commands
I am new to using volumes on databricks. Is there a way to create volume using CLI commands.On the similar note, is there a way to create DBFS directories and subdirectories using single command.for example: I want to copy file here dbfs:/FileStore/T...
- 3830 Views
- 1 replies
- 0 kudos
- 0 kudos
Creates a new volume. The user could create either an external volume or a managed volume. An external volume will be created in the specified external location, while a managed volume will be located in the default location which is specified bythe...
- 0 kudos
- 11030 Views
- 3 replies
- 3 kudos
Resolved! DLT Job Clusters: Continuous vs Triggered Cluster Start Times
Hi there,I'm curious if anyone is able to definitively help me answer how DLT Job Clusters operate/run.For example, the following is my baseline understanding of DLT Job Clusters. If I run a Triggered DLT Pipeline (e.g. daily) the job cluster takes m...
- 11030 Views
- 3 replies
- 3 kudos
- 3 kudos
Ideally one would expect clusters used for DLT pipeline to terminate after the pipeline execution has finished. However, while running in `development` environment, you'll notice it doesn't terminate on its own, whereas in `production` it terminates ...
- 3 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Course
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
ISVPartnership
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
link for labs
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |