- 1015 Views
- 1 replies
- 0 kudos
COPY INTO from Volume failure (rabbit hole)
hey guys, I am stuck on a loading task, and I simply can't spot what is wrong. The following query fails: COPY INTO `test`.`test_databricks_tokenb3337f88ee667396b15f4e5b2dd5dbb0`.`pipeline_state`FROM '/Volumes/test/test_databricks_tokenb3337f88ee6673...
- 1015 Views
- 1 replies
- 0 kudos
- 0 kudos
I see you are reading just 1 file, ensure that there are no zero-byte files in the directory. Zero-byte files can cause schema inference to fail. Double-check that the directory contains valid Parquet files using parquet tools. Sometimes, even if the...
- 0 kudos
- 984 Views
- 1 replies
- 0 kudos
How to identify the goal of a specific Spark job?
I'm analyzing the performance of a DBR/Spark request. In this case, the cluster is created using a custom image, and then we run a job on it.I've dived into the "Spark UI" part of the DBR interface, and identified 3 jobs that appear to account for an...
- 984 Views
- 1 replies
- 0 kudos
- 0 kudos
The spark jobs are decided based on your spark code. You can look at the spark plan to understand what operations each spark job/stage is executing
- 0 kudos
- 2347 Views
- 3 replies
- 1 kudos
Databricks workspace adjust column width
Hi, is it possible to change the column width in the workspace overview? Currently I have a lot of jobs with a name which is too wide for the standard overview and so it not easy to find certain jobs.
- 2347 Views
- 3 replies
- 1 kudos
- 1 kudos
Ahh my mistake! You are right. It can be done only in workflow
- 1 kudos
- 2268 Views
- 2 replies
- 0 kudos
JDBC Invalid SessionHandle with dbSQL Warehouse
Connecting Pentaho Ctools dashboards to Databricks using JDBC to a serverless dbSQL Warehouse, it works fine on the initial load, but then if we leave it idle for awhile and come back we get this error:[Databricks][JDBCDriver](500593) Communication l...
- 2268 Views
- 2 replies
- 0 kudos
- 0 kudos
I should have mentioned that we're using AuthMech=3 and in the JDBC docs (Databricks JDBC Driver Installation and Configuration Guide) I don't see any relevant timeout settings that would apply in that scenario. Am I missing something?
- 0 kudos
- 2427 Views
- 6 replies
- 1 kudos
Unity Catalog for Enterprise level governance
Can we import cataloguing information from other non Databricks workloads into unity catalog? Importing metadata information from Synapse, Redshift, ADF etc. into Unity catalog for end to end lineage and tracking?
- 2427 Views
- 6 replies
- 1 kudos
- 1 kudos
Yes, it is possible, but limited at the moment. This is being implemented and under private preview. There is an API called "Bring-your-own Lineage". You can test it but for that you would need to contact your account team to allow you to use the fea...
- 1 kudos
- 1115 Views
- 1 replies
- 0 kudos
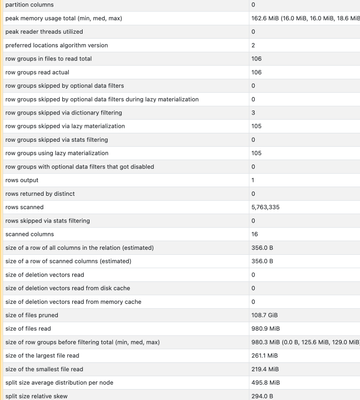
Understanding Photon Row Group Skipping
Hey guys!I am using Photon to do a simple point query on a Liquid Clustered table with the purpose of understanding the statistics. I see that a significant number of files have been pruned (`files pruned`: 1104, `files read`:files read).However I am...
- 1115 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @tomvogel01 , "row groups skipped via lazy materialization" refers to the process where certain row groups are not physically read into memory during query execution. This is due to the ability of Photon to perform filtering at the row group level...
- 0 kudos
- 13124 Views
- 2 replies
- 1 kudos
how to use R in databricks
Hello everyone.I am a new user of databricks, they implemented it in the company where I work. I am a business analyst and I know something about R, not much either, when I saw that databricks could use R I was very excited because I thought that the...
- 13124 Views
- 2 replies
- 1 kudos
- 1 kudos
There are some existing posts about using R in databricks:https://docs.gcp.databricks.com/en/sparkr/index.htmlhttps://docs.databricks.com/en/dev-tools/databricks-connect/cluster-config.htmlOnce you have the correct cluster started (this post is about...
- 1 kudos
- 11268 Views
- 8 replies
- 1 kudos
log signature and input data for Spark LinearRegression
I am looking for a way to log my `pyspark.ml.regression.LinearRegression` model with input and signature ata. The usual example that I found around are using sklearn and they can simply do # Log the model with signature and input example signature =...
- 11268 Views
- 8 replies
- 1 kudos
- 1 kudos
I accidentally stumbled upon this ticket when researching on a similar issue. Note that starting from MLflow 2.15.0 it supports VectorUDT. https://mlflow.org/releases/2.15.0
- 1 kudos
- 714 Views
- 0 replies
- 0 kudos
Patient Risk Score based on health history: Unable to create data folder for artifacts in S3 bucket
Hi All,we're using the below git project to build PoC on the concept of "Patient-Level Risk Scoring Based on Condition History": https://github.com/databricks-industry-solutions/hls-patient-riskI was able to import the solution into Databricks and ru...
- 714 Views
- 0 replies
- 0 kudos
- 1310 Views
- 1 replies
- 0 kudos
Data Bricks x Power BI Report Server
I connected two .pbix files to the local server. In the first, I used Import connectivity, and in the second, Direct Query connectivity. However, I encountered the following problems: Import connection: The data is viewed successfully, but it is not ...


- 1310 Views
- 1 replies
- 0 kudos
- 0 kudos
@Iguinrj11 wrote:I connected two .pbix files to the local server. In the first, I used Import connectivity, and in the second, Direct Query connectivity. However, I encountered the following problems: Import connection: The data is viewed successfull...
- 0 kudos
- 3078 Views
- 5 replies
- 0 kudos
Building a Custom Usage Dashboard using APIs for Job-Level Cost Insights
Since Databricks does not provide individual cost breakdowns for components like Jobs or Compute, we aim to create a custom usage dashboard leveraging APIs to display the cost of each job run across Databricks, Azure Data Factory (ADF), or serverless...
- 3078 Views
- 5 replies
- 0 kudos
- 0 kudos
Hey,Yes, I am not Azure expert but, Databricks REST API can help you extract usage data for serverless resources, allowing you to integrate this information into custom dashboards or external tools like Grafana.On the Azure side, costs related to wil...
- 0 kudos
- 5503 Views
- 4 replies
- 1 kudos
Resolved! Permission denied during write
Hey everyone,I have a pipeline that fetches data from s3 and stores them under the Databricks .tmp/ folder.The pipeline is always able to write around 200 000 files before I get a Permission Denied error. This happens in the following code block: os....
- 5503 Views
- 4 replies
- 1 kudos
- 1 kudos
Thanks for your reply Walter! The filenames are already unique, retries produce the same result and I have the necessary permission as I was able to write the other 200 000 files (with the same program that is running continuous). It does makes sense...
- 1 kudos
- 17570 Views
- 12 replies
- 0 kudos
Resolved! databricks data engineer associate exam
Hello Team, I encountered Pathetic experience while attempting my 1st Databricks certification. I was giving the exam and Abruptly, Proctor asked me to show my desk, everything i showed every corner of my bed.. It was neat and clean with no suspiciou...
- 17570 Views
- 12 replies
- 0 kudos
- 0 kudos
Hi @gokul2 the badge was issued on Dec 2. We just resent the email. Please check your spam. If you continue to have issues, please file a ticket with our support team: https://help.databricks.com/s/contact-us?ReqType=training
- 0 kudos
- 2283 Views
- 3 replies
- 0 kudos
Resolved! How to grant custom container AWS credentials for reading init script?
I'm using a customer container *and* init scripts. At runtime, I get this error:Cluster '...' was terminated. Reason: INIT_SCRIPT_FAILURE (CLIENT_ERROR). Parameters: instance_id:i-0440ddd3a2d5cce79, databricks_error_message:Cluster scoped init script...
- 2283 Views
- 3 replies
- 0 kudos
- 0 kudos
Followup: I got the AWS creds working by amending our AWS role to permit read/write access to our S3 bucket. Woohoo!
- 0 kudos
- 2620 Views
- 3 replies
- 0 kudos
Resolved! Format when specifying docker_image url?
I am providing a custom Docker image to my Databricks/Spark job. I've created the image and uploaded it to our private ECR registry (the URL is `472542229217.dkr.ecr.us-west-2.amazonaws.com/tectonai/mrstevegross-testing:latest`). Based on the docs (h...
- 2620 Views
- 3 replies
- 0 kudos
- 0 kudos
Thanks, that's pretty much what I did; a lot of terraform configuration to get the AWS account set up properly, and now I'm able to tell DBR to load the container. (FWIW, I'm encountering *new* access issues; I started a thread here (https://communit...
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
4 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
1 -
Databricks Apps
1 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks genAI associate
1 -
Databricks JDBC Driver
1 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
Declartive Pipelines
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeBase
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Unity Cataloge
1 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 45 | |
| 40 |