- 6063 Views
- 5 replies
- 0 kudos
Restore deleted databricks jobs and job runs
Hi All,Is there a way to restore deleted databricks jobs?Thank you.
- 6063 Views
- 5 replies
- 0 kudos
- 0 kudos
Hi @iptkrisna ,Currently, there is no option to recover deleted items. In architectures, it not necessary to control or manage the final code available in the system. Instead, the focus should be controlling and managing how code and jobs are deploye...
- 0 kudos
- 4553 Views
- 1 replies
- 1 kudos
Resolved! Unity Catalog : RDD Issue
In our existing notebooks, the scripts are reliant on RDDs. However, with the upgrade to Unity Catalog, RDDs will no longer be supported. We need to explore alternative approaches or tools to replace the use of RDDs. Could you suggest the best practi...
- 4553 Views
- 1 replies
- 1 kudos
- 1 kudos
To transition from using RDDs (Resilient Distributed Datasets) to alternative approaches supported by Unity Catalog, you can follow these best practices and migration strategies: Use DataFrame API: The DataFrame API is the recommended alternative to...
- 1 kudos
- 6291 Views
- 7 replies
- 0 kudos
Resolved! Tutorial docs for running a job using serverless?
I'm exploring whether serverless (https://docs.databricks.com/en/jobs/run-serverless-jobs.html#create-a-job-using-serverless-compute) could be useful for our use case. I'd like to see an example of using serverless via the API. The docs say "To learn...
- 6291 Views
- 7 replies
- 0 kudos
- 1802 Views
- 1 replies
- 1 kudos
Resolved! Is there a cluster option for dashboards?
Hi everyone,I do not want to use 4 DBU/h XS warehouse since I have very tiny data on the new startup. I want to create a minimal cluster and run it as the underlying SQL engine for my dashboard.Thanks.
- 1802 Views
- 1 replies
- 1 kudos
- 1 kudos
Unfortunately no, as dashboards are part of the SQL service on the platform they are designed to work with SQL warehouses only, you can create Notebook dashboards that will be able to work with regular clusters but functionalities will be limited in ...
- 1 kudos
- 3786 Views
- 5 replies
- 1 kudos
Resolved! Databricks workflow with sequenced tasks
I have a continuous workflow. It is continuous because I would like it to run every minute and if it has stuff to do the first task will take several minutes. As I understand, continuous workflows won't requeue while a job is currently running, where...
- 3786 Views
- 5 replies
- 1 kudos
- 1 kudos
Hi @h2p5cq8, No problem! and you can have the queue option disabled to stop it. Go to the Advanced settings in the Job details side panel and toggle off the Queue option to prevent jobs from being queued
- 1 kudos
- 1814 Views
- 1 replies
- 0 kudos
How Development Target works for multiple users?
Hi, I'm using the Databricks asset bundle to deploy my job to Azure Databricks.I want to configure the Databricks bundle so that when anyone runs the Azure pipeline, a job is created under their name in the format dev_username_job.Using a personal ac...
- 1814 Views
- 1 replies
- 0 kudos
- 9617 Views
- 5 replies
- 0 kudos
Azure Databricks Enterprise Application User Impersonation Token Group Claims Issue
Hi all, I am using the Azure Databricks Microsoft Managed Enterprise Application scope (2ff814a6-3304-4ab8-85cb-cd0e6f879c1d/user_impersonation) to fetch an access token on behalf of a user. The authentication process is successful; however, the acce...
- 9617 Views
- 5 replies
- 0 kudos
- 0 kudos
Hi @ahsan_aj, You can modify your token request by adding a claims parameter const claimsRequest = { "access_token": { "groups": null } https://learn.microsoft.com/en-us/security/zero-trust/develop/configure-tokens-gro...
- 0 kudos
- 3183 Views
- 1 replies
- 1 kudos
New Cluster 90% memory already consumed
Hi, seeing this on all new clusters (single or multi-node) I am creating. As soon as the metrics start showing up, the memory consumption shows 90% already consumed between Used and Cached (something like below). This is the case with higher or lower...
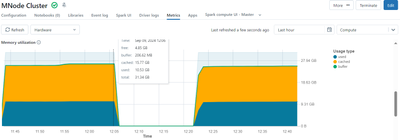
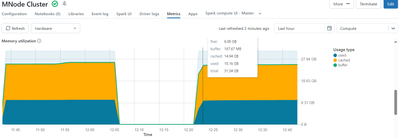
- 3183 Views
- 1 replies
- 1 kudos
- 1 kudos
Hi @AbhishekNegi I understand your concern. The reason for you to see memory consumption before initiating any task and regarding the comment taking time to execute. This is how Spark internally works. The memory consumption observed in a Spark clust...
- 1 kudos
- 13586 Views
- 15 replies
- 3 kudos
Delta Live Tables Permissions
Hi allI'm the owner of delta live tables pipelines but I don't see the option described on documentation to grant permissions for different users. The options available are "settings" and "delete"In the sidebar, click Delta Live Tables.Select the nam...
- 13586 Views
- 15 replies
- 3 kudos
- 3 kudos
Ok might be that the version of the workspaces could be different and the new patch will be implemented soon.
- 3 kudos
- 5383 Views
- 1 replies
- 0 kudos
How the Scale up process done in the databricks cluster?
For my AWS databricks cluster, i configured shared computer with 1min worker node and 3 max worker node, initailly only one worker node and driver node instance is created in the AWS console. Is there any rule set by databricks for scale up the next ...
- 5383 Views
- 1 replies
- 0 kudos
- 0 kudos
Databricks uses autoscaling to manage the number of worker nodes in a cluster based on the workload. When you configure a cluster with a minimum and maximum number of worker nodes, Databricks automatically adjusts the number of workers within this ra...
- 0 kudos
- 3853 Views
- 2 replies
- 0 kudos
Write stream to Kafka topic with DLT
Hi,Is it possible to write stream to Kafka topic with Delta Live Table?I would like to do something like this:@dlt.view(name="kafka_pub",comment="Publish to kafka")def kafka_pub():return (dlt.readStream("source_table").selectExpr("to_json (struct (*)...
- 3853 Views
- 2 replies
- 0 kudos
- 0 kudos
@shashas , is a Kafka sink now available? Where can we find information on setting it up, if yes?
- 0 kudos
- 2615 Views
- 1 replies
- 0 kudos
SQL table convert to R dataframe
I have a table with ~6 million rows. I am attempting to convert this from a sql table on my catalog to an R dataframe to use the tableone package. I separate my table into 3 tables each containing about 2 million rows then ran it through tbl() and as...
- 2615 Views
- 1 replies
- 0 kudos
- 0 kudos
To handle a large SQL table (~6 million rows) and convert it into an R dataframe without splitting it into smaller subsets, you can use more efficient strategies and tools that are optimized for large datasets. Here are some recommendations: 1. Use `...
- 0 kudos
- 1286 Views
- 2 replies
- 1 kudos
How to merge stats from my customer-academy to partner-academy Databricks
Hi,I have been using my customer-academy account from long time, and I recently for a partner-academy account to which I want to sync my stats.It is possible?
- 1286 Views
- 2 replies
- 1 kudos
- 1 kudos
I have mailed to training-support, but no response yet. Just received confirmation email.
- 1 kudos
- 1771 Views
- 1 replies
- 1 kudos
When Databricks Enabling Support for Rust and Go in Notebook
Now #Rust and #GoLang are trending for their efficiency and speed. When can databricks enthusiasts can leverage the power of Rust and Golang in Databricks notebook to create data/ETL pipelines. Any plan at #databricks ?
- 1771 Views
- 1 replies
- 1 kudos
- 1 kudos
Rust is an allowed language at Databricks if you must avoid a JVM process. I can see that the teams are working to provide additional support for Rust which might be available in the near future.
- 1 kudos
- 2233 Views
- 1 replies
- 1 kudos
UC migration : Mount Points in Unity Catalog
Hi All,In my existing notebooks we have used mount points url as /mnt/ and we have notebooks where we have used the above url to fetch the data/file from the container. Now as we are upgrading to unity catalog these url will no longer be supporting a...
- 2233 Views
- 1 replies
- 1 kudos
- 1 kudos
Unfortunately no, mount points are no longer supported with UC, so you will need to modify the URL manually on your notebooks.
- 1 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
4 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
1 -
Databricks Apps
1 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks genAI associate
1 -
Databricks JDBC Driver
1 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
Declartive Pipelines
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeBase
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Unity Cataloge
1 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 45 | |
| 40 |