- 11183 Views
- 2 replies
- 0 kudos
import pandas as pd
from pyspark.sql.types import StringType, IntegerType
from pyspark.sql.functions import col
save_path = os.path.join(base_path, stg_dir, "testCsvEncoding")
d = [{"code": "00034321"}, {"code": "55964445226"}]
df = pd.Data...
- 11183 Views
- 2 replies
- 0 kudos
Latest Reply
@georgeyjy Try opening the CSV as text editor. I bet that Excel is automatically trying to detect the schema of CSV thus it thinks that it's an integer.
1 More Replies
- 4284 Views
- 1 replies
- 0 kudos
Reading file like this "Data = spark.sql("SELECT * FROM edge.inv.rm") Getting this error org.apache.spark.SparkException: Job aborted due to stage failure: Task 10 in stage 441.0 failed 4 times, most recent failure: Lost task 10.3 in stage 441.0 (TID...
- 4284 Views
- 1 replies
- 0 kudos
- 1979 Views
- 0 replies
- 0 kudos
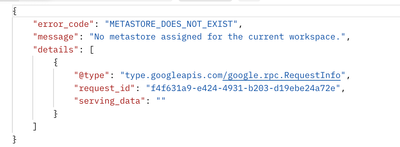
Assessment(Assessment job need to be deployed using Terraform)1.Install latest version of UCX 2.UCX will add the assessment job and queries to the workspace3.Run the assessment using ClusterHow to write code for this by using Terraform. Can anyone he...
- 1979 Views
- 0 replies
- 0 kudos
- 4165 Views
- 2 replies
- 0 kudos
- 4165 Views
- 2 replies
- 0 kudos
Latest Reply
I was able to generate the workspace level token using the databricks cli.I set the following details in the databricks cli profile(.databrickscfg) file: host = https://myworksapce.azuredatabricks.net/ account_id = (my db account id)client_id = ...
1 More Replies