Start your journey with Databricks by joining discussions on getting started guides, tutorials, and introductory topics. Connect with beginners and experts alike to kickstart your Databricks experience.
Hi,In a particular Workflows Job, I am trying to add some data checks in between each task by using If else statement. I used following statement in a notebook to call parameter in if else condition to check logic.{"job_id": XXXXX,"notebook_params": ...
Hi, I have started using databricks recently, and I'm not able find a right solution in the documentations. i have linked multiple repos in my databricks workspace in the repos folders, and I wanted to update the repos with remote AzureDevops reposit...
Hi @Ha2001 , Good Day!
Databricks API has a limit of 10 per second for the /repos/* combined requests in the workspace. You can check the below documentation for the API limit:
https://docs.databricks.com/en/resources/limits.html#:~:text=Git%20fold...
Hi!I am experiencing something that I cannot find in the documentation: in databricks, using the databricks runtime 13.X, when I start a streaming query (using .start method), it creates a new query and while it is running I can execute other code in...
I've lost count of how many different domains and accounts Databricks is requiring for me to use their services. Every domain is requiring its own account username, password, etc., and nothing is synced. I can't even keep track of which email addre...
I try to understand how Databricks computes the model drift when the baseline table is available. What I understood from the documentation is Databricks processes both the primary and the baseline tables according to the specified granularities in th...
Hi,I created first workspace successfully using AWS quickstart method.Now I want to create one more workspace, but quickstart method is not asking IAM role and bucket name and cloudformation stack is failing.
I have a workflow in Databricks and an AutoML pipeline in it.I want to deploy that pipeline in production, but I want to use the shared cluster in production, since AutoML is not compatible with the shared clusters, what can be the workaround.(Is it ...
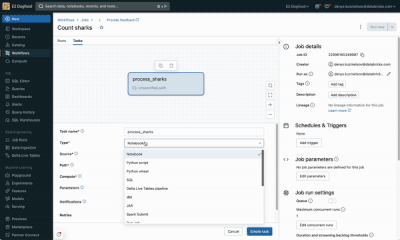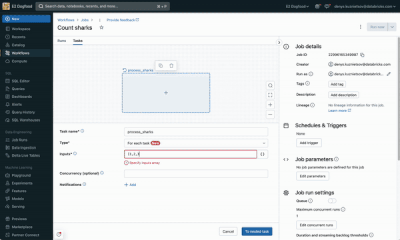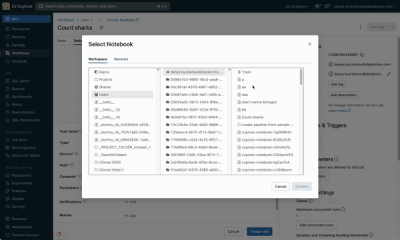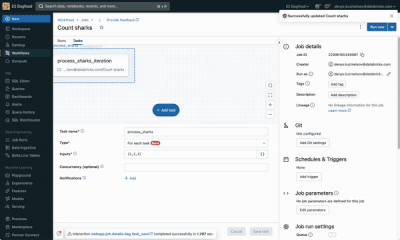
Hi All, I just wanted to try the new Databricks Workflow private preview features (For Each Task).Can someone please guide me on how we can enable it in our workspace as I am having the same use case in my current project where this feature can help ...
Does anyone have a voucher code they do not intend to use and willing to share. I recently lost my job so hard time. I really want to utilize my learnings and give the exam. Thank you.
Hey Databricks - what happened to the jobids that used to be returned from parallel runs? We used them to identify which link matched the output. See attached. How are we supposed to match up the links?
Hey @Databricks, @Retired_mod - waccha doing? Yesterday's "newer version of the app" that got rolled out seems to have broken the parallel runs. The ephemeral notebook is missing. The job ids are missing. What's up? Benedetta
Hi Community i am try to create lzo-codec in my dbfs using:https://docs.databricks.com/en/_extras/notebooks/source/init-lzo-compressed-files.htmlbut i am facing the errorCloning into 'hadoop-lzo'... The JAVA_HOME environment variable is not defined c...
I went through the webinar suggested and the courses mentioned, but I have not received any voucher code for the certification. Can anyone please help. Thank you so much.
Thank you. The link is broken in the response for ticketing portal. I have added a ticket with the help center. Kindly let me know if anything else is needed. Appreciate the help.
When executing the second block under 01-Data-Preparation-and-IndexI get the following error. Please help. AnalysisException: [RequestId=c9625879-339d-45c6-abb5-f70d724ddb47 ErrorClass=INVALID_STATE] Metastore storage root URL does not exist.Please p...
I fixed this issue by providing a MANAGED LOCATION for the catalog - meant updating the _resources/00-init file as follows - spark.sql(f"CREATE CATALOG IF NOT EXISTS {catalog} MANAGED LOCATION '<location path>'")
Hey Databricks, Seems like you changed the way Global Init Scripts work. How come you changed it? My Global Init Script runs great on 12.2LTS but not on the new(er) LTS version 13.3. We don't have Unity Catalog turned on. What's up with that? Ar...
Thank you ChloeBors - I tried upgrading the ubuntu version per your suggestion but got a new error "Can t open lib ODBC Driver 17 for SQL Server file not found 0 SQLDriverConnect". I tried modifying this line to 18: ACCEPT_EULA=Y apt-get install mso...
HelloI have a table in my catalog, and I want to have it as a pandas or spark df. I was using this code to do that before, but I don't know what is happened recently that the code is not working anymore. from pyspark.sql import SparkSession
spark = S...