Engage in discussions on data warehousing, analytics, and BI solutions within the Databricks Community. Share insights, tips, and best practices for leveraging data for informed decision-making.
Here's your Data + AI Summit 2024 - Warehousing & Analytics recap as you use intelligent data warehousing to improve performance and increase your organization’s productivity with analytics, dashboards and insights.
Keynote: Data Warehouse presente...
It will describe about Data models and how to build them on Databricks Platform, especially will Data vault and Data Mesh.Data VaultWhat is Data vault?Data Vault is a modern data modeling technique designed for agile, scalable, and auditable enterpri...
I am embedding a dashboard in my react application using an iframe.https://www.databricks.com/blog/how-embed-aibi-dashboards-your-websites-and-applicationshttps://docs.databricks.com/en/dashboards/index.html#embed-a-dashboard1. How can i let my users...
Hi , Has anyone gotten this working? I am facing the same issue when trying to get the embedded URL working from an iframe in my React application. I think I have all the necessary permissions in place, but still, the Databricks sign-in page opens in...
Hello,We are currently having an issue writing tables to the hive metastore. I've tried to outline what we know/have tried so far, below:Known situation:We have a databricks environment but it does not currently use Unity Catalogue. We instead have a...
Here are some recommendations and tips/tricks:
1. Understanding the Architecture & Common Issues
In legacy Databricks setups, the Hive Metastore is used to manage tables and their metadata. When writing via ODBC (using the Simba Spark driver) or ...
Hi All I'm trying to create a Databricks SQL Endpoint using Terraform with the following resource configuration:resource "databricks_sql_endpoint" "dataproduct_sql_endpoint" {
provider = databricks.workspace
name ...
@SP_6721just a quick heads-up, this is all sorted now. Turns out the compute (warehouse) was just missing a tag. Added it, and everything started working as expected! Thank u !!
Hi Team,I'm encountering the following error when running queries on system tables through a Databricks dashboard using a Serverless SQL Warehouse:[QUERY_RESULT_WRITE_TO_CLOUD_STORE_FAILED] An internal error occurred while uploading the result set to...
Hello @Sitharth Good dayI think the cause would be this: By default, containers are missing from the databricks managed storage accountResolution: you need to create new workspace With this we can close the case.
When trying incorporate an R package into my Spark workflow using the spark_apply() funciton in Sparklyr, I get the error:Error: java.lang.NoSuchMethodError: org.apache.spark.sql.catalyst.encoders.RowEncoder$.apply(Lorg/apache/spark/sql/types/StructT...
Hi @omjohn Can you try downgrading to a Databricks Runtime 13.3 LTS, which uses Spark 3.4.x, officially supported by sparklyr 1.8.1. I believe it would provide a more stable and better-tested integration.
I have the need to replicate existing unity catalog and workspaces from one region to another in databricks. Need help in understanding the different ways in which it can be done
Hey @DM3910 ,It may not be exactly what you need but there is some information in this article around cross-region/platform sharing:https://docs.databricks.com/aws/en/data-governance/unity-catalog/best-practices#cross-region-and-cross-platform-sharin...
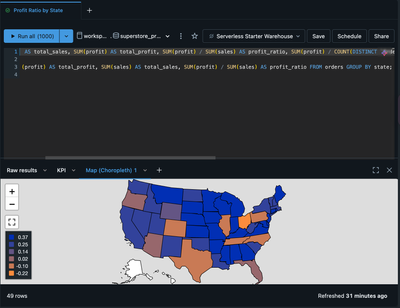
Hello,I'm fairly new to databricks, and wanted to play around with creating dashboards similar to ones I've done in Tableau. With the genie being limited at times in graphs it can create, I used the SQL editor to get what I wanted; however, I'm havin...
Hello @Shivla!
This issue might be related to how the region fields are configured in the choropleth map. If the same State column is assigned to both the Country and State/Province fields, the map may not load properly. Try assigning the state colum...
It is disappointing to see that Databricks is quite at a premature stage and has just marketed the product, but the features are not ready to use yet.Our requirement is fairly straightforward: to create an AI/BI dashboard in Databricks, publish and e...
Hi @Amit-Kumar Have you considered consumer access? If your users are internal users, you can onboard them as workspace users and provision a read-only access to dashboards and Genie. Alternatively, you could use embedded credentials approach for acc...
The data selection is part of loaded data if I want to filter out the data I'm not able to filter it out I believe this is glitch in the data bricks dashboard UI
Attempting to create a Python UDF and receiving an error stating it's not supported in my environment.running on SQL Serverless Cluster - Preview (v 2025.16)[FEATURE UNAVAILABLE]Python UDTF is not supported in your environment. To use this feature, p...
Currently Serverless supports only scaler valued function not table valued function. also you need to provide the catalog and schema in the function.You can create using a pro computecreate function {catalog_name}.{schema_name}._rrr_taxonomy_test()RE...
According to the pricing page, the minimum cost in using this product is 1 DBU per hour.Often times, access to such tables comes in bursts with many periods of idle time. How is infrequent use factored into the pricing? This is also important for set...
As far as I can tell, the minimum charge for an online table is DBU-cost x 24 x 30 per month, i.e. around $720 per month.Is the 15-minute scale-down window documented somewhere?With a 15-minute scale-down window, assuming just one access per hour, th...
Hello,We recently modified some table names and used the UC Lineage to identify the users that were accessing these particular tables to notify. However, it seems we broke our Genie Space that was using that table. As best as I can tell, queries from...
As of now, system tables like information_schema.table_usage or query_history do not log Genie Space queries. They primarily log interactive and scheduled queries from notebooks, dashboards, and the SQL editor.you will need to rely on Genie configura...
Bug SummaryTitle: Spark SQL internal error when executing SQL code in the Azure Databricks SQL Editor DescriptionWhen executing SQL code in the Azure Databricks SQL Editor, a Spark SQL internal error is returned. Steps to ReproduceCopy and paste th...