Engage in discussions on data warehousing, analytics, and BI solutions within the Databricks Community. Share insights, tips, and best practices for leveraging data for informed decision-making.
Hello,I have an Azure sql warehouse serverless instance that I can connect to using databricks-sql-connector. But, when I try to use pyspark and jdbc driver url, I can't read or write.See my code belowdef get_jdbc_url(): # Define your Databricks p...
Hi @amelia1, The error messages you provided indicate that there might be a problem with the log4j configuration and formatting. Additionally, the repeated column names suggest that there might be an issue with how the data is being retrieved.
Her...
We're creating a report with Power BI using data from our AWS Databricks workspace. Currently, I can view the report on Power BI (service) after publishing. Is there a way to change the data source connection, e.g. if I want to change the data source...
According to the documentation the WHERE predicate in a DELETE statement should supports subqueries, including IN, NOT IN, EXISTS, NOT EXISTS, and scalar subqueries.if I try to run a query like: DELETE FROM dev.gold.table AS trg
WHERE EXISTS (
...
@diego_poggioli Can you try selecting a 'year_month_version' column from the view instead of select * DELETE FROM dev.gold.table AS trg
WHERE year_month_version IN (select year_month_version FROM v_distinct_year_month_version)
When we create a Lakeview dashboard, the visuals show truncated data. I want to create a dashboard using the entire dataset because the charts do not display the exact values needed for accurate analysis.
Hello @Akshay_Petkar ,
The FrontEnd (FE) rendering is a limit that determines what data we render on the FE that has been returned by the BackEnd (BE). Render all button allows you to render all the data on the FE that has been returned by the BE.
Re...
Hi Guys,I have a JSON as the below structure where the key is as decimal.{ "5.0": { "a": "15.92", "b": 0.0, "c": "15.92", "d": "637.14" }, "0.0": { "a": "15.92", "b": 0.0, "c": "15.92", "d": "637.14" } }schema_of_json returns the following:STRUCT<`0....
Hello @data_guy ,
I've performed a reproduction of your scenario and could successfully select all data. Please check screenshot below:
This is the source code:
import json
data_values = {
"5.0": { "a": "15.92", "b": 0.0, "c":...
Need help in Azure Databricks VNet architecture with Power BI. Our Databricks setup is based on No Public IP. Does anyone has a architecture that can support the Databricks setup in VNet Injection and Power BI tool accessing the Databricks.
I am very new to DB. Can someone show me how to resolve the error below please? Assistant The error message you're encountering indicates that when creating a catalog, you need to specify a managed storage location for it. This is a requirement in o...
If your root metastore bucket is not configured then you need to provide a managed location when creating a catalog in UC. https://docs.databricks.com/en/data-governance/unity-catalog/create-catalogs.html#create-a-catalog
Materialized views are currently public preview (as of May 2024). Is there a planned date for GA?Also the limitations section for Azure notes: Databricks SQL materialized views are not supported in the South Central US and West US 2 regions.Will thi...
Hi, I am looking for a way to get usage statistics from Databricks (Data Science & Engineering and SQL persona). For example: I created a table. I want to know how many times a specific user queried that table.How many times a pipeline was triggered?...
You can use System Tables, now available in Unity Catalog metastore, to create the views you described. https://docs.databricks.com/en/admin/system-tables/index.html
SQL serverless now use cache even after termination thanks to the remote cache. You can benefit from 1 min auto-termination when still utilizing cache benefits.
Databricks asset bundles, now in Public Preview, enable end-to-end data, analytics, and ML projects to be expressed as a collection of source files. This makes it simpler to apply data engineering best practices such as source control, code review, t...
Will a Databricks Asset Bunldes (DAB) implementation take place in the cloud (Browser - Workspace)?Personally, I work on a developer VM in a closed network where it is very difficult to install software (Databricks CLI) because it has to be requested...
I'm creating dashboard with multiple visualizations from a notebook.Whenever I add a new visualization, the default position in dashboard is top left which mess up all the format I did for previous graph. Is there a way to default add to the bottom o...
@shan_chandra I'm using Lakeview dashboard. In dbx notebook, there is Add to dashboard > button on the right of each visualization. It's super handy. Actually I have this issue solved.
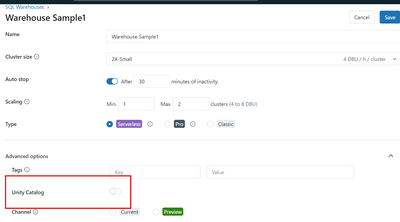
Manual ApproachWe can Update SQL Warehouse manually in Databricks.Click SQL Warehouses in the sidebarIn Advanced optionsWe can find Unity Catalog toggle button there! While Updating Existing SQL Warehouse in Azure to enable unity catalog using terraf...
Hello Raphael,Thank you for the update and for looking into the feature request. I appreciate your efforts in following up on this matter.If possible, could you please provide me with any updates or insights you receive from the Terraform team regard...
We have been evaluating Databricks SQL and its capability to be used as DW. We are using Unity catalog in our implementation.There seems to be a functionality mismatch between Azure and AWS versions as where table rename is supported on Azure side, i...