Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: How i can add ADLS Gen2 - OAuth 2.0 as Cluster...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2023 05:22 AM
Hi All,
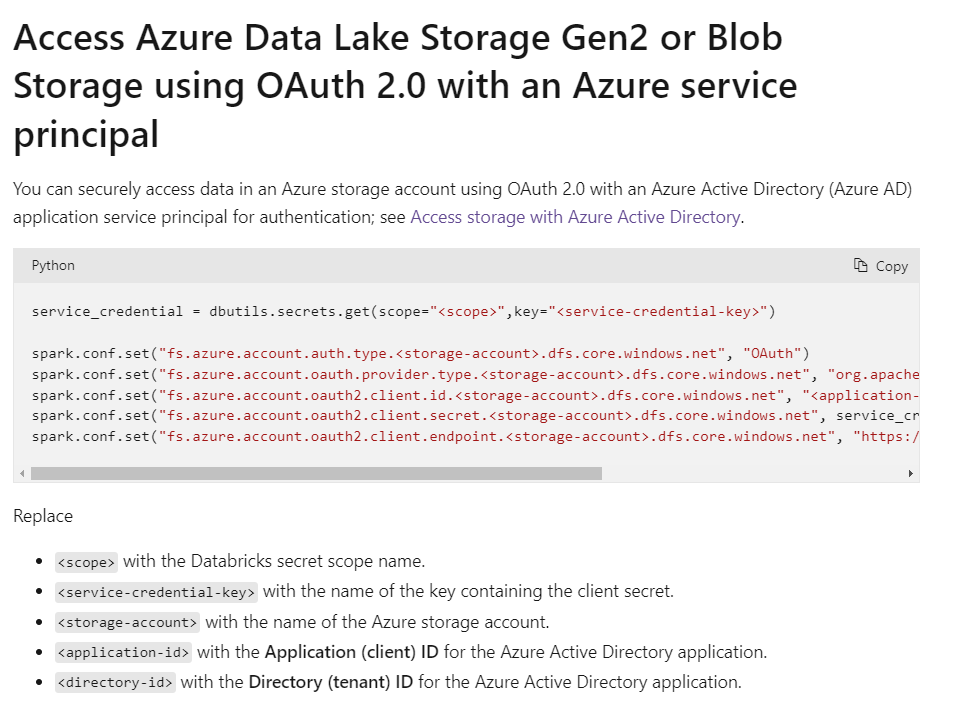
Kindly help me , how i can add the ADLS gen2 OAuth 2.0 authentication to my high concurrency shared cluster.

I want to scope this authentication to entire cluster not for particular notebook.
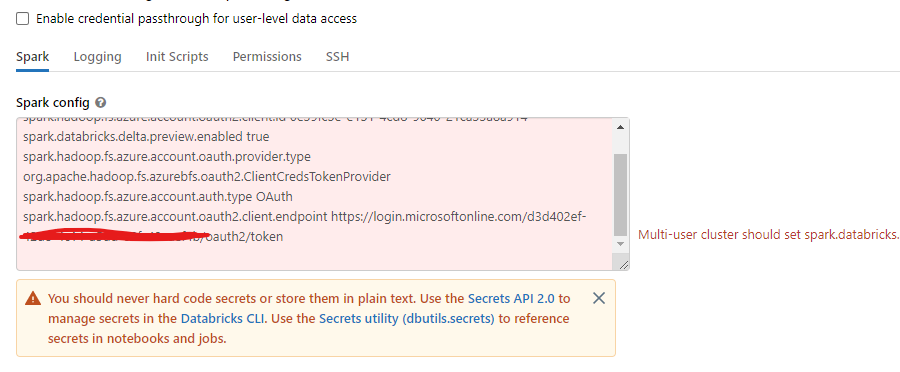
Currently i have added them as spark configuration of the cluster , by keeping my service principal credentials as Secrets. But still am getting this following warning.

Kindly advice me what's the better alternate secure solution.
Note: Am creating the cluster using Terraform
Regards,
Sunil
Labels:


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-12-2023 10:06 AM
Yes , i have configured them in spark configuration.
But i am yet to configure in cluster policy as he recommended
8 REPLIES 8
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2023 05:33 AM
It looks like you've removed some config entries from Spark Config that are required for multi-user cluster to work.
Try to only add the required config rather than overwriting.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2023 07:19 AM
Thanks for the response @Daniel Sahal
But that's not an issue , i have enabled the Access mode as Shared by setting this property for my highly concurrent cluster and its working
ADLS gen2 OAuth is also working.
But my question , is it secured or any other better option where i can store the Cluster level scope
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2023 01:44 PM
Have you considered using session scopes instead of cluster scopes? I have a function stored at databricks. functions. azure. py that does this:
from pyspark.sql import SparkSession
def set_session_scope(scope: str, client_id: str, client_secret: str, tenant_id: str, storage_account_name: str, container_name: str) -> str:
"""Connects to azure key vault, authenticates, and sets spark session to use specified service principal for read/write to adls
Args:
scope: The azure key vault scope name
client_id: The key name of the secret for the client id
client_secret: The key name of the secret for the client secret
tenant_id: The key name of the secret for the tenant id
storage_account_name: The name of the storage account resource to read/write from
container_name: The name of the container resource in the storage account to read/write from
Returns:
Spark configs get set appropriately
abfs_path (string): The abfss:// path to the storage account and container
"""
spark = SparkSession.builder.getOrCreate()
try:
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
except ImportError:
import IPython
dbutils = IPython.get_ipython().user_ns["dbutils"]
client_id = dbutils.secrets.get(scope = scope, key = client_id)
client_secret = dbutils.secrets.get(scope = scope, key = client_secret)
tenant_id = dbutils.secrets.get(scope = scope, key = tenant_id)
spark.conf.set(f"fs.azure.account.auth.type.{storage_account_name}.dfs.core.windows.net", "OAuth")
spark.conf.set(f"fs.azure.account.oauth.provider.type.{storage_account_name}.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set(f"fs.azure.account.oauth2.client.id.{storage_account_name}.dfs.core.windows.net", client_id)
spark.conf.set(f"fs.azure.account.oauth2.client.secret.{storage_account_name}.dfs.core.windows.net", client_secret)
spark.conf.set(f"fs.azure.account.oauth2.client.endpoint.{storage_account_name}.dfs.core.windows.net", f"https://login.microsoftonline.com/{tenant_id}/oauth2/token")
abfs_path = "abfss://" + container_name + "@" + storage_account_name + ".dfs.core.windows.net/"
return abfs_pathAnd its usage is like this:
from databricks.functions.azure import set_session_scope
# Set session scope and connect to abfss to read source data
client_id = "databricks-serviceprincipal-id"
client_secret = "databricks-serviceprincipal-secret"
tenant_id = "tenant-id"
storage_account_name = "your-storage-account-name"
container_name = "your-container-name"
folder_path = "" #path/to/folder/
abfs_path = set_session_scope(
scope = scope,
client_id = client_id,
client_secret = client_secret,
tenant_id = tenant_id,
storage_account_name = storage_account_name,
container_name = container_name
)
file_list = dbutils.fs.ls(abfs_path + folder_path)Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 03:25 AM
Thanks for the response. But in this case every time we have to execute this function right.
I am expecting something similar to Mount point (unfortunately -Databricks not recommends mount point for ADLS) , where at the time of cluster creation itself we will provide connection to our storage account.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 03:42 AM
Yes, the approach to set it in the spark config you used is correct and according to best practices. Additionally, you can put it in cluster policy so it will be for all clusters.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 04:49 AM
thanks hubert... could you kindly guide , how i can add that in the cluster policy ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 01:29 AM
- error is because of missing default settings (create new cluster and do not remove them),
- the warning is because secrets should be put in secret scope, and then you should reference secrets in settings
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-12-2023 10:06 AM
Yes , i have configured them in spark configuration.
But i am yet to configure in cluster policy as he recommended
Announcements





{kind=link}
{kind=link}
{kind=link}
Related Content
- Is there a way to natively mount external Iceberg REST Catalogs (e.g., BigLake) in Unity Catalog? in Data Engineering
- Memory error in LightGBM training data processing in Machine Learning
- Unity Catalog storage credential fails although same Access Connector works in another credential in Data Engineering
- Transitioning from ADF to Databricks Workflows: Best Practices in a Multi-Workspace (dev-prod) in Data Engineering
- I built a free 11-tab Cost Observability Dashboard as a Databricks App — open source in Administration & Architecture