Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- How to create connection between Databricks & BigQ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 01:42 AM
Hi,
I would like to connect our BigQuery env to Databricks, So I created a service account but where should I configure the service account in Databricks? I read databricks documention and it`s not clear at all.
Thanks for your help


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 03:46 AM
without the pointy brackets. they are placeholders for values.
so unless you want to enter a variable which you already declared (like credentials in your example), put the double quotes.
15 REPLIES 15
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 03:17 AM
https://docs.databricks.com/external-data/bigquery.html
Can you elaborate what is not clear?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 03:21 AM
yeah, part number 2 - setup Databricks, there is the below code
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client_email>
spark.hadoop.fs.gs.project.id <project_id>
spark.hadoop.fs.gs.auth.service.account.private.key <private_key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private_key_id>
what should it replace instead of <base64-keys> ? the google service account key (json) ? if yes what part of it ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 03:24 AM
the base64-keys is generated from the json key file:
To configure a cluster to access BigQuery tables, you must provide your JSON key file as a Spark configuration. Use a local tool to Base64-encode your JSON key file. For security purposes do not use a web-based or remote tool that could access your keys.
The JSON key file is created right above the following section:
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 03:35 AM
So basically it should look like this :
credentials <adfasdfsadfadsfsdafsd>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <user@service.com>
spark.hadoop.fs.gs.project.id <project-dd>
spark.hadoop.fs.gs.auth.service.account.private.key <fdsfsdfsdgfd>
spark.hadoop.fs.gs.auth.service.account.private.key.id <gsdfgsdgdsg>
? Do I need to add "" ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 03:46 AM
without the pointy brackets. they are placeholders for values.
so unless you want to enter a variable which you already declared (like credentials in your example), put the double quotes.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 04:17 AM
Thanks werners.
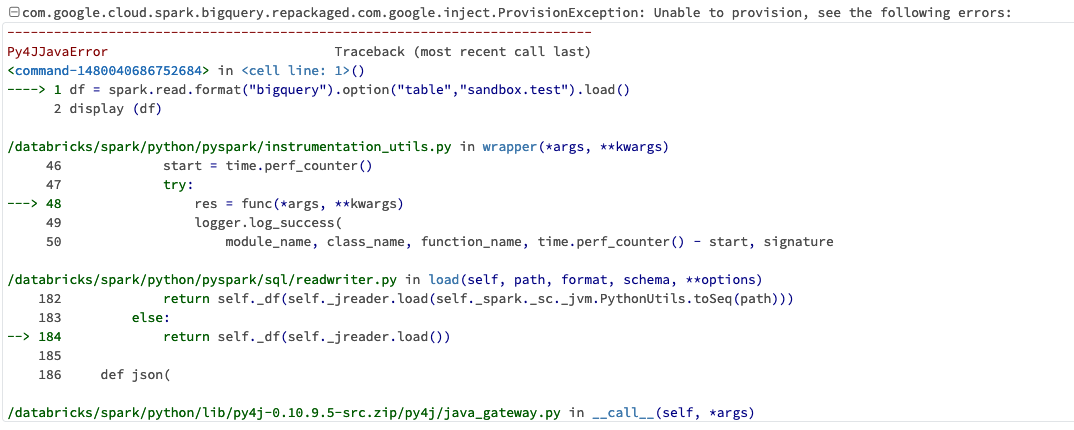
it now working, when I'm runnning the below script:
df = spark.read.format("bigquery").option("table","sandbox.test").load()
im getting the below error:
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 04:18 AM


Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 04:25 AM
are you sure the path to the table is correct?
the example is a bit different:
"bigquery-public-data.samples.shakespeare"
<catalog>.<db>.<table>
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 04:33 AM
I also changed the path to "test_proj.sandbox.test".
the error is :
A project ID is required for this service but could not be determined from the builder or the environment. Please set a project ID using the builder.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 04:38 AM
I guess something still has to be configured on BigQuery.
can you check this thread?
https://github.com/GoogleCloudDataproc/spark-bigquery-connector/issues/40
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 04:43 AM
Works 🙂
Thanks werners, many thanks .
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-02-2023 07:53 PM
Thank you. For me, setting parent project ID solved it. This is also in the documentation
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
I didn't have to set the various spark.hadoop.fs.gs config variables for the cluster, as it seemed content with the base64 credentials.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 03:21 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 03:23 AM
I familar with this doc, it is not clear (please find my previous comment)
Announcements





{kind=link}
{kind=link}
Related Content
- Databricks Apps - "App Not Available" error with locationId parameter missing in Data Engineering
- oreign Iceberg tables via HMS federation fail with browse_only_table on all compute — request Public in Data Engineering
- CREATE CONNECTION - Support for Community Connections? in Data Engineering
- Can I connect Fabric Data Agent With Databricks Genie One as external connection in Administration & Architecture
- Can I connect Fabric Data Agent With Databricks Genie One as external connection in Data Governance