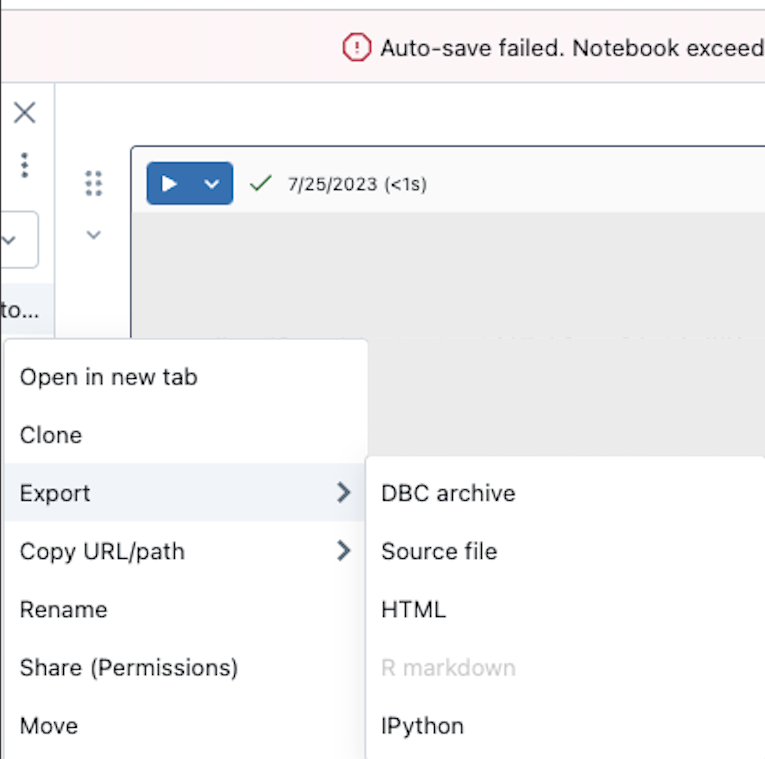
When a Databricks Notebook exceeds size limit, it suggests to `clone/export without results`.
This is exactly what I want to do, but the current web UI does not provide the ability to bypass/skip the results in either the `clone` or `export` context menus. Additional note: I do not want to clear the outputs of the current notebook.
Screenshots provided for visual context. Not sure if there are other places that I may have overlooked.
Fact finding performed so far:
Thank you in advance for any insights you can share on achieving this goal.







{kind=link}
{kind=link}