Need some help in choosing between where to do deduplication of data. So I have sensor data in blob storage that I'm picking up with Databricks Autoloader. The data and files can have duplicates in them.Which of the 2 options do I choose?Option 1:Cre...
@peter_mcnally You can use watermark to pick the late records and send only the latest records to the bronze table. This will ensure that you always have the latest information in your bronze table.This feature is explained in detail here - https://w...
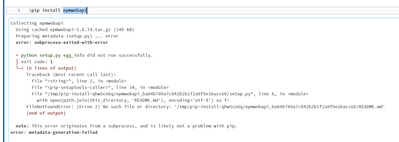
I am trying to run a simple training script using HF's transformers library and am running into the error `Distributed package doesn't have nccl built in` error.Runtime: DBR 13.0 ML - SPark 3.4.0 - Scala 2.12Driver: i3.xlarge - 4 coresNote: This is a...
Hi @anastassia_kor1,For CPU-only training, TrainingArguments has a no_cuda flag that should be set.For transformers==4.26.1 (MLR 13.0) and transformers==4.28.1 (MLR 13.1), there's an additional xpu_backend argument that needs to be set as well. Try u...
databricks workspace export_dir / export command with overwrite option enabled adds non-existent changes in the target directory. 1. It introduces new line deletion and 2. add/deletion of MAGIC comments despite not making any meaningful changes in th...
I am encountering this issue as well and it did not happen previously. Additionally, you see this pattern if you are using repos internally and make a change to a notebook in another section.
If you are streaming from a Delta table, you can specify the starting version or timestamp. You can refer the document for complete detail: https://docs.databricks.com/structured-streaming/delta-lake.html#specify-initial-position
Just wondering about the dev flow when building Delta Live Tables. I write my code in the notebook so it would be useful to be able to test it out from within that environment.
Hi all, I'm trying to connect to MongoDB using the Databricks notebook. I keep getting the error that my MongoDB uri is invalid. The uri works when connecting from my local machine using the Rust driver. I pretty much followed the tutorial that was g...
Hello,as i'm trying to create a CI/CD for the project, I'm finding myself stuck.Tried to upload the Notebooks from my Azure DevOps Release and I'm getting 403-forbidden access.I used 'cat ~/.databrickscfg file and matched with the local config that I...
Hey everyone! I can totally relate to the frustration of encountering authentication issues when setting up a CI/CD pipeline. It's great that you're able to import the notebooks locally, but facing difficulties on Azure DevOps can be quite puzzling.F...
Is there a cluster health dashboard which has the details of the total number of running interactive cluster, the total number of job clusters? Also Flag clusters with issues.
My source code is in the VSTS repository and I am using PAT token to connect VSTS from Azure data bricks notebook and then building packages and installing my cluster. For the production environment, I can't use PAT token, so is there any way to conn...
Hey everyoneI've been working with Azure DevOps and VSTS repositories, and I can relate to the challenges of connecting them securely. thushar, I understand your concern about using a PAT token for production environments. Fortunately, there is indee...
I am looking through Google Cloud Platform and I am looking to get started with Databricks on GCP. Happy if anyone can point me in the direction that can provide guidance on how to get started.Thansk
Hey boyelana Databricks on Google Cloud Platform is definitely an interesting and powerful combination, and I'm thrilled to see that you're looking to get started with it, boyelana!To begin your journey with Databricks on GCP, there are a few steps y...
Is there a way to get an existing personal access token via python ? Either through and sdk or a rest endpoint ? Or is the only way to do that to store the PAT in a key vault and retrieve it via a secret scope ? Thank you !
Hi @Ajay-Pandey
Hope everything is going great.
Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so ...
KB Feedback DiscussionIn addition to the Databricks Community, we have a Support team that maintains a Knowledge Base (KB). The KB contains answers to common questions about Databricks, as well as information on optimisation and troubleshooting.These...