Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Pyspark - How do I convert date/timestamp of forma...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-28-2023 04:51 AM
Hi all,
I've a dataframe with CreateDate column with this format:
CreateDate
/Date(1593786688000+0200)/
/Date(1446032157000+0100)/
/Date(1533904635000+0200)/
/Date(1447839805000+0100)/
/Date(1589451249000+0200)/
and I want to convert that format to date/timestamp, so the excepted output will be:
CreateDate
2020-07-03 14:31:28 +02:00
2015-10-28 11:35:57 +01:00
2018-08-10 12:37:15 +02:00
2015-11-18 09:43:25 +01:00
2020-05-14 10:14:09 +02:00
I have this query in SQL that gives the desired output and that can help to develop:
cast(convert(VARCHAR(30), DATEADD(Second, convert(BIGINT, left(replace(replace(CreateDate, '/date(', ''), ')/', ''), 13)) / 1000, '1970-01-01 00:00:00'), 20) + ' ' + '+' + left(right(replace(replace(CreateDate, '/date(', ''), ')/', ''), 4), 2) + ':' + right(replace(replace(CreateDate, '/date(', ''), ')/', ''), 2) AS DATETIMEOFFSET(0)) AS CreateDateCan anyone please help me in achieving this?
Thank you!
Labels:
- Labels:
-
Azure databricks
-
Pyspark


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-28-2023 08:34 PM
Hi @Bruno Franco ,
Can you please try the below code, hope it might for you.
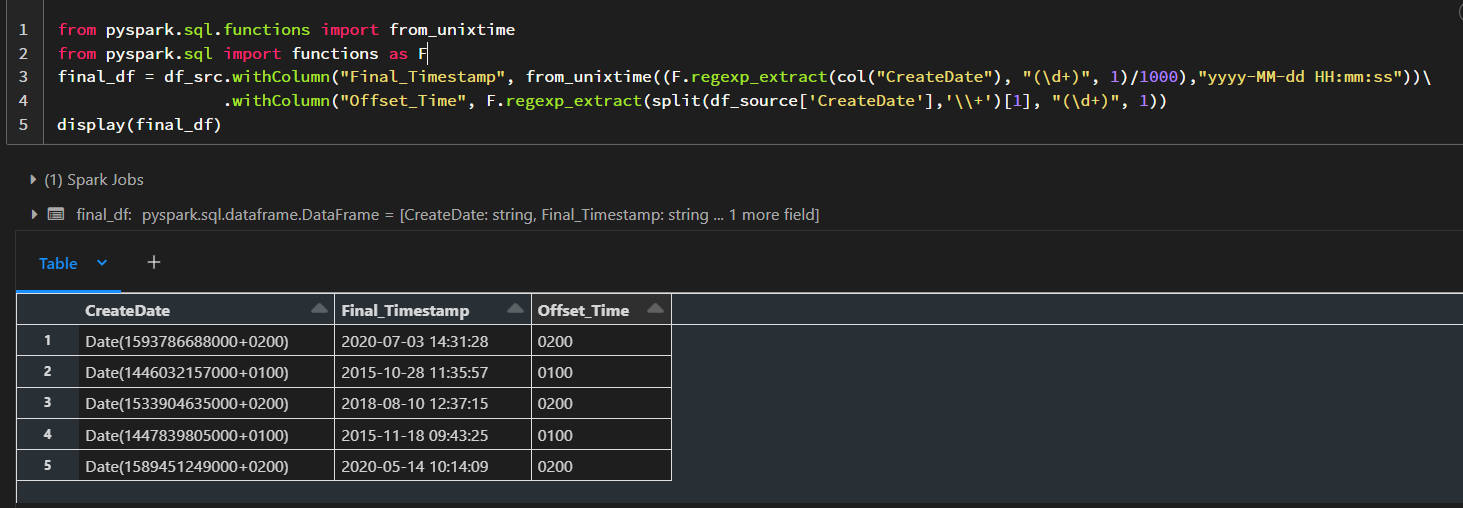
from pyspark.sql.functions import from_unixtime
from pyspark.sql import functions as F
final_df = df_src.withColumn("Final_Timestamp", from_unixtime((F.regexp_extract(col("CreateDate"), "(\d+)", 1)/1000),"yyyy-MM-dd HH:mm:ss"))\
.withColumn("Offset_Time", F.regexp_extract(split(df_source['CreateDate'],'\\+')[1], "(\d+)", 1))
display(final_df)
I have divided the value with 1000 because from_unixtime takes arguments in seconds, and your
timestamp is in milliseconds.
Happy Learning!!
Thanks for reading and like if this is useful and for improvements or feedback please comment.
3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-28-2023 08:34 PM
Hi @Bruno Franco ,
Can you please try the below code, hope it might for you.
from pyspark.sql.functions import from_unixtime
from pyspark.sql import functions as F
final_df = df_src.withColumn("Final_Timestamp", from_unixtime((F.regexp_extract(col("CreateDate"), "(\d+)", 1)/1000),"yyyy-MM-dd HH:mm:ss"))\
.withColumn("Offset_Time", F.regexp_extract(split(df_source['CreateDate'],'\\+')[1], "(\d+)", 1))
display(final_df)
I have divided the value with 1000 because from_unixtime takes arguments in seconds, and your
timestamp is in milliseconds.
Happy Learning!!
Thanks for reading and like if this is useful and for improvements or feedback please comment.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2023 03:43 AM
Thanks a lot @Ratna Chaitanya Raju Bandaru , I picked up your code and I did this:
final_df = df.withColumn("CreateDateNew", concat(from_unixtime((F.regexp_extract(col("CreateDate"), "(\d+)", 1)/1000),"yyyy-MM-dd HH:mm:ss"), lit(" "), regexp_replace(regexp_extract("CreateDate", re, 2), "(\\d{2})(\\d{2})" , "$1:$2" )))
and I got the desired output:

Once again, thanks and kind regards 👍
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2023 04:00 AM
Hi @Bruno Franco ,
Glad it helped you
Happy Learning!!
Thanks for reading and like if this is useful and for improvements or feedback please comment.
Announcements





{kind=link}
{kind=link}
Related Content
- StatusCode.UNIMPLEMENTED error: DatabricksConnect library using AKS/PySpark to calling Spark cluster in Data Engineering
- Aspiring Data Engineer offering free project support in exchange for mentorship 🚀 in Data Engineering
- How does Databricks handle registration and discovery of custom PySpark data sources in SDPs? in Data Engineering
- PySpark AnalysisException: Ambiguous reference to field t when parsing nested JSON in Data Engineering
- STTM as a Metadata Contract in Databricks in Data Engineering