Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Spark last window dont flush in append mode
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Spark last window dont flush in append mode
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-01-2023 04:31 AM
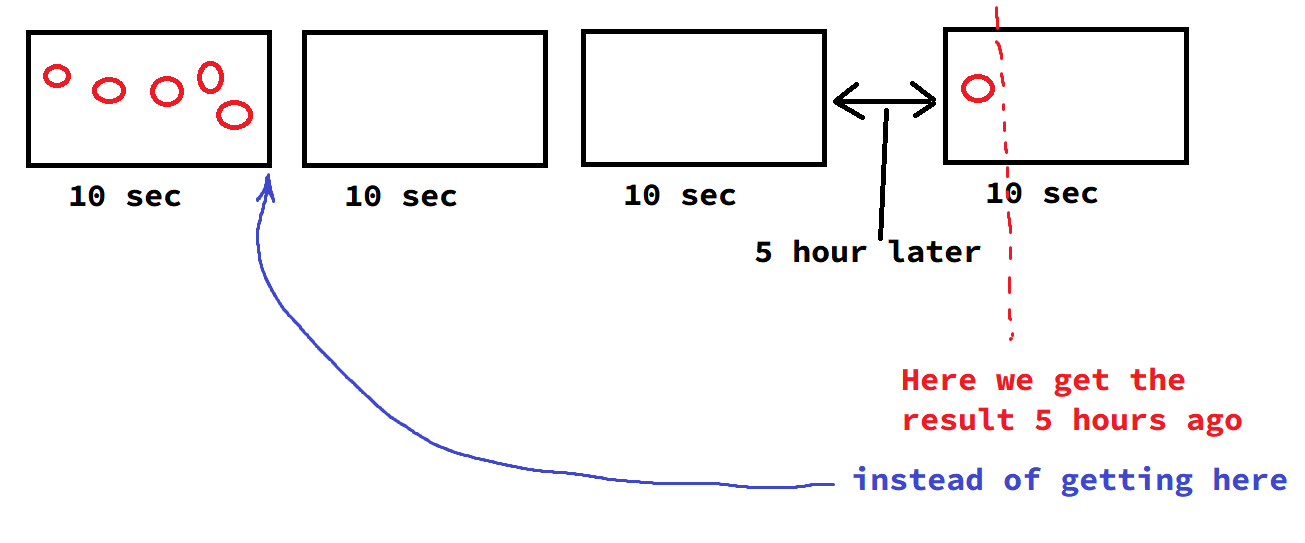
The problem is very simple, when you use TUMBLING window with append mode, then the window is closed only when the next message arrives (+watermark logic).
In the current implementation, if you stop incoming streaming data, the last window will NEVER close and we LOSE the last window data.
How can we force the last window to close\flush if new data stops incoming?
Business situation:
Worked correctly and new messages stop incoming and next message come in 5 hours later and the client will get the message after 5 hours instead of the 10 seconds delay of window.

Spark v3.3.2 Code of problem:
kafka_stream_df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", KAFKA_BROKER) \
.option("subscribe", KAFKA_TOPIC) \
.option("includeHeaders", "true") \
.load()
sel = (kafka_stream_df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.select(from_json(col("value").cast("string"), json_schema).alias("data"))
.select("data.*")
.withWatermark("dt", "1 seconds")
.groupBy(window("dt", "10 seconds"))
.agg(sum("price"))
)
console = sel \
.writeStream \
.trigger(processingTime='10 seconds') \
.format("console") \
.outputMode("append")\
.start()
Labels:


4 REPLIES 4
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-04-2023 06:42 PM
@Dev Podavan :
The issue you're facing is related to the behavior of Apache Spark's window operations in a streaming context when using a tumbling window with an append output mode. By default, the window will not close or flush until a new message arrives within the window's duration, which can result in data being delayed or lost if there is a gap in incoming data.
To force the window to close or flush even if new data stops incoming, you can set a watermark on the window operation with a timeout value. The watermark specifies a threshold time after which the window is considered complete, even if no new data arrives.
In your code, you have already defined a watermark on the "dt" column with a timeout of 1 second using the withWatermark function. However, you may need to adjust the watermark timeout value to a larger value that allows for any potential delays in the data arrival. For example, you can try increasing the watermark timeout to 5 minutes or longer, depending on the expected maximum delay in your data.
Here's an updated code snippet with a watermark timeout of 5 minutes:
kafka_stream_df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", KAFKA_BROKER) \
.option("subscribe", KAFKA_TOPIC) \
.option("includeHeaders", "true") \
.load()
sel = (kafka_stream_df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.select(from_json(col("value").cast("string"), json_schema).alias("data"))
.select("data.*")
.withWatermark("dt", "5 minutes") # Increase watermark timeout to 5 minutes
.groupBy(window("dt", "10 seconds"))
.agg(sum("price"))
)
console = sel \
.writeStream \
.trigger(processingTime='10 seconds') \
.format("console") \
.outputMode("append")\
.start()With this updated code, even if new data stops incoming, the window will close or flush after the watermark timeout of 5 minutes, ensuring that data is not delayed indefinitely or lost. You can adjust the watermark timeout value as needed based on your specific use case and data characteristics.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-04-2023 11:44 PM
Hi @Dev Podavan
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-13-2023 03:37 AM
No, the problem remains the same. The meaning doesn't change because you increased the timeout a little bit. As the window did not close, and does not close until a new message arrives
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2024 01:00 AM
Do you have any solution for this ?
Announcements





{kind=link}
Related Content
- Streaming read and writing with aggregation in Data Engineering
- delta as streaming source, can the reader reads only newly appended rows? in Data Engineering
- Regarding : How to use Row_number() in dlt pipelines in Data Engineering
- [UNITY_CREDENTIAL_SCOPE_MISSING_SCOPE] Missing Credential Scope. Unity Credential Scope id not foun in Data Engineering
- DLT Streaming With Watermark fails, suggesting I should add watermarks in Data Engineering