- 2234 Views
- 1 replies
- 0 kudos
What causes affect QB Won't Open and how to fix it?
What Can Be Causing QB Won't Open Issue and How Can I Fix It? I need help immediately to fix this annoying issue! Has anybody else had such problems with QB refusing to open? My personal attempts at troubleshooting have yielded no results. I would be...
- 2234 Views
- 1 replies
- 0 kudos
- 0 kudos
@markwilliam8506 If your QB won't open even after multiple tries, you might be facing some common error messages. This scenario can be a result of damaged program files or a faulty installation process, among other possible reasons. The error message...
- 0 kudos
- 7682 Views
- 1 replies
- 0 kudos
Serving GPU Endpoint, can't find CUDA
Hi everyone !I'm encountering an issue while trying to serve my model on a GPU endpoint.My model is using deespeed that needs I got the following error : "An error occurred while loading the model. CUDA_HOME does not exist, unable to compile CUDA op(...
- 7682 Views
- 1 replies
- 0 kudos
- 16819 Views
- 3 replies
- 2 kudos
Resolved! Idle Databricks trial costs me $1/day on AWS
I created a 14-day trial account on Databricks.com and linked it to my AWS. I'm aware that DBUs are free for 14 days, but any AWS charges are my own. I created one workspace, and the CloudFormation was successful. I haven't used it for two days and t...
- 16819 Views
- 3 replies
- 2 kudos
- 2 kudos
I also faced the same not sure how to disable or limit the usage.
- 2 kudos
- 2285 Views
- 1 replies
- 0 kudos
Feature Store with Spark Pipeline
Hi,I am using a spark pipeline having stages VectoreAssembler, StandardScalor, StringIndexers, VectorAssembler, GbtClassifier. And then logging this pipeline using feature store log_model function as follows:fe = FeatureStoreClient() // I have tried ...
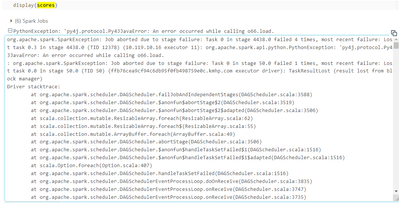
- 2285 Views
- 1 replies
- 0 kudos
- 4184 Views
- 5 replies
- 2 kudos
Problem updating a one time run Job
I'm creating a series of runs using the /api/2.1/jobs/runs/submit, I wanted to add some tags for more control on the cost and usage, but I notice it's not an option. My first idea was using /api/2.1/jobs/update but it returns that it doesn't have any...
- 4184 Views
- 5 replies
- 2 kudos
- 2 kudos
It could be, but I can still list the job permissions, so it's creating some kind of job... Is there a way of adding from the begining/updating tags into that job?
- 2 kudos
- 2701 Views
- 0 replies
- 0 kudos
Deploy mlflow model to Sagemaker
Hi,I am trying to deploy mlflow model in Sagemaker. My mlflow model is registered in Databrick.Followed below url to deploy and it need ECR for deployment. For ECR, either I can create custom image and push to ECR or its mentioned in below url to get...
- 2701 Views
- 0 replies
- 0 kudos
- 3904 Views
- 0 replies
- 0 kudos
SQL query on information_schema.tables via service principal
Hi,I have a simple python notebook with below code ----query = "select table_catalog, table_schema, table_name from system.information_schema.tables where table_type!='VIEW' and table_catalog='TEST' and table_schema='TEST'"test = spark.sql(query)disp...
- 3904 Views
- 0 replies
- 0 kudos
- 2001 Views
- 0 replies
- 0 kudos
Notebook Editor Theme Not Being Retained after Repo Screen
tldr: Notebook selected "Editor theme (New)" is not being retained after viewing "push code code to repo" screen.I believe I have the answer to this issue.What's occurring and why:1. User selects: View --> Editor theme --> <<theme>> (ie: Monokai)2. U...
- 2001 Views
- 0 replies
- 0 kudos
- 3064 Views
- 1 replies
- 1 kudos
reading databricks tables
Hello,Currently I have created databricks tables in the hive_metastore.databasesTo read these tables using a select * query inside the databricks notebook, I have to make sure the databrcks cluster is started.Question is to do with reading the databr...
- 3064 Views
- 1 replies
- 1 kudos
- 3557 Views
- 1 replies
- 0 kudos
Resolved! ETL Advice for Large Transactional Database
I have a SQL server transactional database on an EC2 instance, and an AWS Glue job that pulls full tables in parquet files into an S3 bucket. There is a very large table that has 44 million rows, and records are added, updated and deleted from this t...
- 3557 Views
- 1 replies
- 0 kudos
- 0 kudos
If you have a CDC stream capability, you can use the APPLY CHANGES INTO API to perform SCD1, or SCD2 in a Delta Lake table in Databricks. You can find more information here. This is the best way to go if CDC is a possibility.If you do not have a CD...
- 0 kudos
- 10685 Views
- 2 replies
- 0 kudos
Connect to Databricks using Java SDK through proxy
I'm trying to connect to databricks from java using the java sdk and get cluster/sqlWarehouse state. I'm able to connect and get cluster state from my local. But, once I deploy it to the server, my company's network is not allowing the connection. We...
- 10685 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @Nagasundaram You can make use of the below init script inorder to use a proxy server with Databricks cluster. The content of the init script can be added at "Workspace/shared/setproxy.sh" ================================================== v...
- 0 kudos
- 1794 Views
- 1 replies
- 0 kudos
Can I use databricks principals on databricks connect 12.2?
Hi community,Is it possible to use Databricks service principals for authentication on Databricks connect 12.2 to connect my notebook or code to Databricks compute, rather than using personal access token? I checked the docs and got to know that upgr...
- 1794 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @Retired_modThanks for your response. I was able to generate the token of the service principal following this doc, later saved it in the <Databricks Token> variable prompted when running databricks-connect configure command in terminal. And was a...
- 0 kudos
- 11226 Views
- 1 replies
- 0 kudos
How to add instance profile permission to all user via databricks-sdk workspace client
How to add instance profile permission to all user via databricks-sdk workspace client. Just like terraform where we can give "users" for all users , how can we don same using databricks-sdk workspace-client. I cannot find permission for instance pro...
- 11226 Views
- 1 replies
- 0 kudos
- 1296 Views
- 0 replies
- 0 kudos
How managed tables are useful in Madalian Archtecture
I am having basic question, As managed tables doesnt store their data into ADLS Gen2. But in our architcture we created 3 containers in ADLS Gen2 (Bronze, Silver and Gold) . If I chose managed tables then neither metadata nor data doesnt store into ...
- 1296 Views
- 0 replies
- 0 kudos
- 12656 Views
- 2 replies
- 1 kudos
UCX Installation
We aim to streamline the UCX installation process by utilizing Databricks CLI and automating the manual input of required details at each question level .Could you please guide us how can we achieve to automate the parameter's while installation? wha...
- 12656 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi Team, We don't see option at UCX command level passing parameters as json /config file, could you please help me in this case how we can automate the installation.
- 1 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
4 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
1 -
Databricks Apps
1 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks genAI associate
1 -
Databricks JDBC Driver
1 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
Declartive Pipelines
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeBase
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Unity Cataloge
1 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 45 | |
| 40 |