- 4747 Views
- 1 replies
- 0 kudos
Access Delta sharing from Azure Data Factory
I recently got access to delta sharing and I am looking to access the data from the tables in share through ADF. I used linked services such as REST API and HTTP and successfully established connection using the credential file token and http path, h...
- 4747 Views
- 1 replies
- 0 kudos
- 0 kudos
Hey, I think you'll need to use a Databricks activity instead of Copy See : https://learn.microsoft.com/en-us/azure/data-factory/connector-overview#integrate-with-more-data-storeshttps://learn.microsoft.com/en-us/azure/data-factory/transform-data-dat...
- 0 kudos
- 5230 Views
- 4 replies
- 1 kudos
Redefine ETL strategy with pypskar approach
Hey everyone!I've some previous experience with Data Engineering, but totally new in Databricks and Delta Tables.Starting this thread hoping to ask some questions and asking for help on how to design a process.So I have essentially 2 delta tables (sa...
- 5230 Views
- 4 replies
- 1 kudos
- 1 kudos
Hi @databird , You can review the code of each demo by opening the content via "View the Notebooks" or by exploring the following repo : https://github.com/databricks-demos (you can try to search for "merge" to see all the occurrences, for example) T...
- 1 kudos
- 3425 Views
- 2 replies
- 0 kudos
There is no certification number in my Databricks certificate that i had received after passing the
I enrolled myself for the Databricks data engineer certification recently and gave a shot at the exam and i did clear it successfully. I have received the certificate in the form of a pdf file along with a URL in which i can see my certificate and ba...
- 3425 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @vinay076 Thanks for asking! Our support team can provide you with a credential ID. Please file a ticket with our support team, give them your email associated with your certification, and they can get you the credential ID.
- 0 kudos
- 11230 Views
- 5 replies
- 4 kudos
Resolved! How obtain a list of workflows in Databricks?
I need to obtain a list of my Databricks workflows with their job IDs in a notebook Databricks
- 11230 Views
- 5 replies
- 4 kudos
- 4 kudos
Hi @VabethRamirez , Also, instead of using directly the API, you can use databricks Python sdk : %pip install databricks-sdk --upgrade dbutils.library.restartPython()from databricks.sdk import WorkspaceClient w = WorkspaceClient() job_list = w.jobs...
- 4 kudos
- 2356 Views
- 1 replies
- 0 kudos
Can api for query history /api/2.0/sql/history/queries return data which is older than 30 days?
I am using this api but it is returning the data for only last 30 days. Can this api return data which is older than 30 days?
- 2356 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @RahulChaubey, The query history system table was announced during the Q1 roadmap webinar (see the recording, 32:25). There is a chance that it will provide data with a horizon beyond 30 days. Meanwhile, you can enable system tables - I hope some ...
- 0 kudos
- 4061 Views
- 2 replies
- 0 kudos
Does Delta Table can be the source of streaming/auto loader?
Hi,Since the Auto Loader only accept "append-only" data as the source, I am wondering if the "Delta Table" can also be the source.Does VACCUM(deleting stale files) or _delta_log(creating nested and different file format than parquet) going to break A...
- 4061 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @QPeiran, Auto-loader is a feature that allows to integrate files into the Data Platform. Once your data is stored into the Delta Table, you can rely on spark.readStream.table("<my_table_name>") to continuously read from the table. Take a look at ...
- 0 kudos
- 2307 Views
- 1 replies
- 0 kudos
Handling large volumes of streamed transactional data using DLT
We have a data stream from event hub with approximately 10 million rows per day (into one table) - these records are insert only (no update). We are trying to find a solution to aggregate / group by the data based on multiple data points and our requ...
- 2307 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi, please find below a set of resources I believe relevant for you. Success stories You can find the success stories of companies leveraging the streaming on Databricks here. Videos Introduction to Data Streaming on the Lakehouse : Structured Stream...
- 0 kudos
- 6135 Views
- 2 replies
- 0 kudos
Resolved! Rearrange tasks in databricks workflow
Hello,There is anyway to rearrange tasks in databricks workflow?.I would like that line that join the two marked tasks doesn't pass behind the other tasks. It is posible that this line by one side?Thanks.

- 6135 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @chemajar, Take a look at Databricks Asset Bundles. It allows you to streamline the development of complex workflows using a yaml definition. In case you need to change the task dependencies, you can rearrange the flow as you need just change the ...
- 0 kudos
- 4092 Views
- 2 replies
- 0 kudos
Do we pay just for qurery run duration while using databricks serverless sql ?
While using databricks serverless sql to run queries does we only pay for the compute resources during the run duration of the query ?
- 4092 Views
- 2 replies
- 0 kudos
- 2374 Views
- 1 replies
- 0 kudos
- 2374 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi, can you clatify what is your aim ? Maybe there is no need to use DB SDK at all ?
- 0 kudos
- 4655 Views
- 3 replies
- 0 kudos
Unity Catalog view access in Azure Storage account
Hi,I have my unity catalog in Azure Storage account and I can able to access table objects but I couldn't find my views that were created on top of those table. 1. I can can access Delta tables & related views via Databricks SQL and also find the tab...
- 4655 Views
- 3 replies
- 0 kudos
- 0 kudos
Hi, Couple of options are possible : Use Databricks to do the complex SQL queries (joins, unions, etc) and write to a staging Delta Table. Then use DataFlow to read from that staged table. Orchestrate all of this using ADF or even Databricks Workflo...
- 0 kudos
- 4124 Views
- 2 replies
- 1 kudos
PowerBI Tips
Does anyone have any tips for using PowerBI on top of databricks? Any best practices you know of or roadblocks you have run into that should be avoided?Thanks.
- 4124 Views
- 2 replies
- 1 kudos
- 1 kudos
Hey, Use Partner Connect to establish a connection to PBI Consider to use Databricks SQL Serverless warehouses for the best user experience and performance (see Intelligent Workload Management aka auto-scaling and query queuing, remote result cache, ...
- 1 kudos
- 2649 Views
- 1 replies
- 0 kudos
Connecting to DataBricks Sql warehouse from .net
Hi,How can I connect to DataBricks sql warehouse from .net application. Kr
- 2649 Views
- 1 replies
- 0 kudos
- 0 kudos
Hey, Please, take a look at Statement Execution API Best,
- 0 kudos
- 2753 Views
- 1 replies
- 1 kudos
Resolved! Can we get SQL Serverless warehouses monitoring data using APIs or logs ?
I am looking for a possible way to get the autoscaling history data for SQL Serverless Warehouses using API or logs.I want something like what we see in monitoring UI.
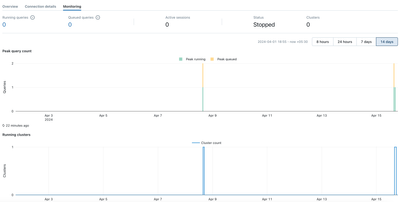
- 2753 Views
- 1 replies
- 1 kudos
- 1 kudos
Hi Rahul, you need to perform two actions : Enable system tables schema named "compute" (how-to, take a look on the page, it's highly possible that you'll find other schemas useful too)Explore system.compute.warehouse_events table Hope this helps. B...
- 1 kudos
- 15133 Views
- 4 replies
- 1 kudos
column "id" is of type uuid but expression is of type character varying.
Hello,I'm trying to write to Azure PostgreSQL flexible database from Azure Databricks, using PostgreSQL connector in Databricks Runtime in 12.2LTS.I'm using df.write.format("postgresql").save() to write to PostgreSQL database, but getting the follow...
- 15133 Views
- 4 replies
- 1 kudos
- 1 kudos
Yes, this stack overflow was my reference too and adding below option made load go with no error on UUID data type in postgres columnSpoiler.option(stringtype, "unspecified").option(stringtype, "unspecified")https://stackoverflow.com/questions/409739...
- 1 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Course
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
ISVPartnership
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
link for labs
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |