- 13304 Views
- 9 replies
- 1 kudos
How to move a metastore to a new Storage Account in unity catalog?
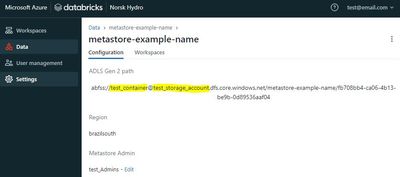
Hello, I would like to change the Metastore location in Databricks Account Console. I have one metastore created that is in an undesired container/storage account. I could see that it's not possible to edit a metastore that is already created. I coul...
- 13304 Views
- 9 replies
- 1 kudos
- 1 kudos
@TugrulA we repopulated our SQL warehouse by rerunning all Pipelines (Delta Live Tables) that read our raw data from an Azure storage account (different than the Metastore storage container) and write the bronze/silver/gold tables to the (new) Metast...
- 1 kudos
- 3830 Views
- 2 replies
- 0 kudos
Databricks Unity Catalog Metastore
Hey everyone,I deleted my Unity Catalog metastore and now want to point it to another Azure storage account (ADLS). However, once a metastore is created, its storage location cannot be changed. Therefore, I deleted the existing metastore and created ...
- 3830 Views
- 2 replies
- 0 kudos
- 0 kudos
Hey TugrulA - 1. Deleting a Unity Catalog Metastore permanently removes all associated objects, and the new metastore wont automatically include original objects. Unfortunately automatic recover is not possible. While UC allows UNDROP for individual ...
- 0 kudos
- 1784 Views
- 2 replies
- 0 kudos
Resolved! Trying to understand why a cluster reports as "terminating" right after being created
We use a "warmup" mechanism to get our DBR instance pool into a state where it has at-least-N instances. The logic is:For N repetitions:Request a new DBR cluster in the pool (which causes the pool to request an AWS instance)Wait for the cluster to re...
- 1784 Views
- 2 replies
- 0 kudos
- 0 kudos
Aha, found it. I monitored the pool status via the DBR UI, and when a cluster *started* being provisioned, I clicked into it. Then I looked at the event log, and found useful information about failed steps. The underlying error was indeed AWS related...
- 0 kudos
- 3455 Views
- 3 replies
- 1 kudos
Resolved! Databricks AWS permission question
Hello,I'm currently using Databricks on AWS for some basic ETL where the resulting data is stored as Hive external delta tables.Even though Unity catalog is disabled, table access control is disabled for the workspace, and the cluster is running with...
- 3455 Views
- 3 replies
- 1 kudos
- 1 kudos
@Lennart Glad to hear it helped! If you think this solves your question, please consider marking it as the accepted answer so it can assist other users as well.Best regards, Isi
- 1 kudos
- 2180 Views
- 1 replies
- 0 kudos
Linking Workspace IDs to Names in Billing Schema
Hi everyone,We recently enabled UC and the Billing system table to monitor our usage and costs. We've successfully set up a dashboard to track these metrics for each workspace. The usage table includes the workspace_id, but I'm having trouble finding...
- 2180 Views
- 1 replies
- 0 kudos
- 0 kudos
I got this from their older version of the dashboard. dbdemos uc-04-system-tablesWhen everything is executed, go to your graph in the dashboard, click three dots in the top right, select in my case "View dataset:usage_overview" then paste/modify sql ...
- 0 kudos
- 1127 Views
- 1 replies
- 0 kudos
Unable to Access Data Apps/Templates in Databricks Workspace
Hi,We are currently unable to view any of the standard apps/templates (such as Data Apps, Chatbot, and Hello World) within our Databricks workspace.Workspace Details:Workspace Name: KdataaiWorkspace URL: https://1027317917071147.7.gcp.databricks.comC...
- 1127 Views
- 1 replies
- 0 kudos
- 0 kudos
Hello @aishwaryakdataa! Could you please verify if the Databricks Apps service is enabled in your workspace? You may also need to review the App configuration settings and ensure that the appropriate roles and permissions are in place to access the t...
- 0 kudos
- 2940 Views
- 3 replies
- 0 kudos
Unable to add a microsoft security group as Workspace Admin
I'm a workspace admin for a databricks workspace. I can add a microsoft security group in the workspace. When I click on the group to view it I can view the members of the group same in the Azure AD reflecting correctly but it throws an error on the ...
- 2940 Views
- 3 replies
- 0 kudos
- 0 kudos
@pranav5 This issue usually occurs because of how Databricks handles group provisioning via SCIM, especially with external groups from Azure AD.SCIM 404 Error: This generally means Databricks cannot find a matching SCIM identity for the Azure AD grou...
- 0 kudos
- 1998 Views
- 2 replies
- 0 kudos
JDBC Driver cannot connect when using TokenCachePassPhrase property
Hello all, I'm looking for suggestions on enabling the token cache when using browser based SSO login. I'm following the instructions found here: Databricks-JDBC-Driver-Install-and-Configuration-Guide For my users, I would like to enable the token ca...
- 1998 Views
- 2 replies
- 0 kudos
- 0 kudos
For the error encountered (Cannot invoke "java.nio.file.attribute.AclFileAttributeView.setAcl(...)" because "<local6>" is null) might be permission or file system issues where the token cache store is being accessed. When EnableTokenCache=0, the to...
- 0 kudos
- 5734 Views
- 3 replies
- 1 kudos
Databricks Notebook says "Connecting.." for some users
For some users, after clicking on a notebook the screen says "connecting..." and the notebook does not open.The users are using Chrome browser and the same happens with Edge as well.What could be the reason?
- 5734 Views
- 3 replies
- 1 kudos
- 1 kudos
Even I am facing the same issue. It always keep saying, opening the notepad. Luckily once it is opened and when connected with the cluster, then its getting timeout.
- 1 kudos
- 5226 Views
- 8 replies
- 1 kudos
Notebook Detached Error: exception when creating execution context: java.net.SocketTimeoutException:
Hello Community,I have been facing this issue since yesterday. After attaching the cluster to a notebook and running a cell, I get the following error in the community edition of the databricks:Notebook detached:exception when creating execution cont...
- 5226 Views
- 8 replies
- 1 kudos
- 1 kudos
Hi All,I am also facing issue.if anyone knows how to resolve this, please post the solution here.
- 1 kudos
- 4348 Views
- 7 replies
- 0 kudos
preloaded_docker_images: how do they work?
At my org, when we start a databricks cluster, it oftens takes awhile to become available (due to (1) instance provisioning, (2) library loading, and (3) init script execution). I'm exploring whether an instance pool could be a viable strategy for im...
- 4348 Views
- 7 replies
- 0 kudos
- 0 kudos
Hello, when we specify docker image with credentials in instance pool configuration, should we also specify credentials in cluster configuration?. as we already have image pulled into the pool instance.
- 0 kudos
- 4755 Views
- 2 replies
- 0 kudos
Is there an automated way to strip notebook outputs prior to pushing to github?
We have a team that works in Azure Databricks on notebooks.We are not allowed to push any data to Github per corporate policy.Instead of everyone having to always remember to clear their notebook outputs prior to commit and push, is there a way this ...
- 4755 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi,pushing to GitHub isn’t allowed, but clearing notebook outputs before internal version control is still important, you can automate this process by using a pre-commit hook or a script within your internal CI/CD pipeline (if one exists). Tools like...
- 0 kudos
- 3413 Views
- 3 replies
- 1 kudos
Replacing Excel with Databricks
I have a client that currently uses a lot of Excel with VBA and advanced calculations. Their source data is often stored in SQL Server.I am trying to make the case to move to Databricks. What's a good way to make that case? What are some advantages t...
- 3413 Views
- 3 replies
- 1 kudos
- 1 kudos
To add on this, my team and I have been using Databricks in an enterprise environment to replace Excel based calculation relying on SQL stored data with Calculations served as model serving endpoints (API) - the initial 'translation' work can be tedi...
- 1 kudos
- 1554 Views
- 2 replies
- 1 kudos
Resolved! Search page to search code inside .py files
Hello, hope you are doing good.When on the search page, it seems it's not searching for code inside .py files but rather only the filename.Is there an option somewhere I'm missing to be able to search inside .py files ? Best,Alan
- 1554 Views
- 2 replies
- 1 kudos
- 1 kudos
Hello, so it seems Databricks does not allow it - an easy workaround for us is to search directly on our Azure DevOps Repos.
- 1 kudos
- 1550 Views
- 1 replies
- 0 kudos
COMMUNITY EDITION CLUSTER DETACH JAVA.UTIL.TIMEOUTEXCEPTION.
Hi folks i was exploring the databricks community edition and came across a cluster issue mostly because of jdbc driver java.util.timeoutexception . basically the cluster connects and executes for 15 sec or so which is a socket limit and disables any...
- 1550 Views
- 1 replies
- 0 kudos
- 0 kudos
@Kishore23 paturnpikewrote:Hi folks i was exploring the databricks community edition and came across a cluster issue mostly because of jdbc driver java.util.timeoutexception . basically the cluster connects and executes for 15 sec or so which is a so...
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |