- 16784 Views
- 12 replies
- 13 kudos
Resolved! Uploading local file
Since, last two day i getting an error called "ERROR OCCURRED WHEN PROCESSING FILE:[OBJECT OBJECT]" While uploading any "csv" or "json" file from my local system but it shows or running my previous file but give error after uploading a new file

- 16784 Views
- 12 replies
- 13 kudos
- 13 kudos
If you are using databricks community edition, the error you are facing is because the file you are trying to upload contains PII or SPII data ( Personally Identifiable Information OR Sensitive Personally Identifiable Information) words like dob, To...
- 13 kudos
- 5048 Views
- 3 replies
- 5 kudos
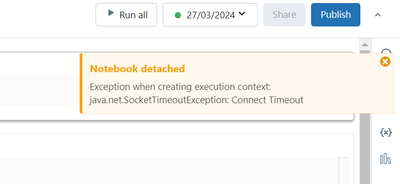
Getting java.util.concurrent.TimeoutException: Timed out after 15 seconds on community edition
Im using databricks communtiy edition for learning purpose and im whenever im running notebook, im getting:Exception when creating execution context: java.util.concurrent.TimeoutException: Timed out after 15 seconds databricks.I have deleted cluster ...
- 5048 Views
- 3 replies
- 5 kudos
- 5 kudos
@stevieg95 The issue is that, you've run the notebook with old connector connected to your old deleted cluster with same names, when you ran a terminated cluster, you see the error. First delete existing cluster and logout and detach old cluster as b...
- 5 kudos
- 3652 Views
- 6 replies
- 0 kudos
Issue with Multiple Stateful Operations in Databricks Structured Streaming
Hi everyone,I'm working with Databricks structured streaming and have encountered an issue with stateful operations. Below is my pseudo-code: df = df.withWatermark("timestamp", "1 second") df_header = df.withColumn("message_id", F.col("payload.id"))...
- 3652 Views
- 6 replies
- 0 kudos
- 0 kudos
This should according to this blog post basically work, right? However, I'm getting the same errorMultiple Stateful Streaming Operators | Databricks BlogOr am I missing something? rate_df = spark.readStream.format("rate").option("rowsPerSecond", "1")...
- 0 kudos
- 2889 Views
- 3 replies
- 0 kudos
Databricks Apps have become unavailable
We've become unable to access or renable Apps in our workspace. As of yesterday the tab "Apps" has dissapeared from the compute page in our workspaces. Additionally the toggle that we originally used to enable the public preview for apps has dissapea...
- 2889 Views
- 3 replies
- 0 kudos
- 0 kudos
Hi @Renu_, thanks for the advice. I just did a double check in the account panel but I couldn't find anything there that seemed related to enabling Apps that we have access to. Would you happen to know which specific preview/setting we would need to ...
- 0 kudos
- 2250 Views
- 2 replies
- 2 kudos
Resolved! Unstructured Data (Images) training in Databricks
I'm looking for a solution where1. Need a delta table that saves the pointers(path) of the images in volume2. Train a Pytorch, tensorflow or keras model with the data from delta lake.I tried multiple methods :1. Storing the data as vectors or binary ...
- 2250 Views
- 2 replies
- 2 kudos
- 2 kudos
I managed to find a few solution accelerators that are in the ballpark, albeit not exact, to what you are trying to accomplish. Have a look: 1. https://www.databricks.com/solutions/accelerators/digital-pathology 2. https://www.databricks.com/resour...
- 2 kudos
- 1766 Views
- 1 replies
- 0 kudos
How do I display output from applyinPandas function?
I'm using databricks version 13.3. I have a function which I'm calling by using the applyInPandas function. I need to see the attributes of my df dataset which I'm using inside my function. My sample code looks likedef train_model(df):# Copy input Da...
- 1766 Views
- 1 replies
- 0 kudos
- 0 kudos
Here are some idead/approaches to consider: To inspect the attributes of a df dataset within a function used in applyInPandas on a Databricks Runtime 13.3 cluster, you can use debugging techniques that help you explore the structure and content of ...
- 0 kudos
- 1245 Views
- 1 replies
- 0 kudos
Assistance Needed with Databricks DQX Framework for Data Quality
Hi Community Experts,I hope this message finds you well. Our team is currently working on enhancing data quality within our Databricks environment and we are utilizing the Databricks DQX framework for this purpose. We are seeking detailed guidance a...
- 1245 Views
- 1 replies
- 0 kudos
- 0 kudos
Hello @shubham_007! It looks like this post duplicates the one you recently posted. A response has already been provided there. I recommend continuing the discussion in that thread to keep the conversation focused and organised
- 0 kudos
- 1684 Views
- 3 replies
- 0 kudos
The case of the phantom files!
I developed a notebook that uses *.py files as module imports. On my cluster, the logic in the notebook works fine, my custom modules get loaded, code executes.Using an AzDO pipeline, I deploy the notebook and supporting files to a separate workspac...
- 1684 Views
- 3 replies
- 0 kudos
- 0 kudos
Got it.My background is not SWE, I have always been a 'data guy', but I definitely appreciate a proper dev workflow (ci/cd, git integration, tests).When we started using databricks like 7 or 8 years ago, we went for notebooks as this got us up to spe...
- 0 kudos
- 3646 Views
- 3 replies
- 2 kudos
UI menu customisation
If I want to customize the UI menu so some users/groups can't for example create jobs or make experiments etc.As I see it, when unity catalog is enabled, everyone can create jobs (If they have attach to cluster permission). But in my organization, th...
- 3646 Views
- 3 replies
- 2 kudos
- 2 kudos
I would also like a way to customize what users see when they log in. For example we don't want most of them to even have the option of creating a Genie Space so ideally we could simply remove "Genie" from their menu
- 2 kudos
- 6776 Views
- 11 replies
- 14 kudos
Smaller dataset causing OOM on large cluster
I have a pyspark job reading the input data volume of just ~50-55GB Parquet data from a delta table on Databricks. Job is using n2-highmem-4 GCP VM and 1-15 worker with autoscaling on databricks. Each workerVM of type n2-highmem-4 has 32GB memory and...
- 6776 Views
- 11 replies
- 14 kudos
- 14 kudos
Next, use the repartition(n) to increase your dataframe to twice the number you got earlier. For example, if num_partitions was 30, then repartition(60) prior to running your query. With half the data in each Memory Partition, I'm guessing you won't...
- 14 kudos
- 13273 Views
- 9 replies
- 1 kudos
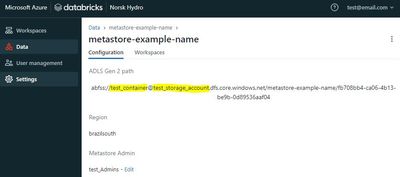
How to move a metastore to a new Storage Account in unity catalog?
Hello, I would like to change the Metastore location in Databricks Account Console. I have one metastore created that is in an undesired container/storage account. I could see that it's not possible to edit a metastore that is already created. I coul...
- 13273 Views
- 9 replies
- 1 kudos
- 1 kudos
@TugrulA we repopulated our SQL warehouse by rerunning all Pipelines (Delta Live Tables) that read our raw data from an Azure storage account (different than the Metastore storage container) and write the bronze/silver/gold tables to the (new) Metast...
- 1 kudos
- 3806 Views
- 2 replies
- 0 kudos
Databricks Unity Catalog Metastore
Hey everyone,I deleted my Unity Catalog metastore and now want to point it to another Azure storage account (ADLS). However, once a metastore is created, its storage location cannot be changed. Therefore, I deleted the existing metastore and created ...
- 3806 Views
- 2 replies
- 0 kudos
- 0 kudos
Hey TugrulA - 1. Deleting a Unity Catalog Metastore permanently removes all associated objects, and the new metastore wont automatically include original objects. Unfortunately automatic recover is not possible. While UC allows UNDROP for individual ...
- 0 kudos
- 1775 Views
- 2 replies
- 0 kudos
Resolved! Trying to understand why a cluster reports as "terminating" right after being created
We use a "warmup" mechanism to get our DBR instance pool into a state where it has at-least-N instances. The logic is:For N repetitions:Request a new DBR cluster in the pool (which causes the pool to request an AWS instance)Wait for the cluster to re...
- 1775 Views
- 2 replies
- 0 kudos
- 0 kudos
Aha, found it. I monitored the pool status via the DBR UI, and when a cluster *started* being provisioned, I clicked into it. Then I looked at the event log, and found useful information about failed steps. The underlying error was indeed AWS related...
- 0 kudos
- 3432 Views
- 3 replies
- 1 kudos
Resolved! Databricks AWS permission question
Hello,I'm currently using Databricks on AWS for some basic ETL where the resulting data is stored as Hive external delta tables.Even though Unity catalog is disabled, table access control is disabled for the workspace, and the cluster is running with...
- 3432 Views
- 3 replies
- 1 kudos
- 1 kudos
@Lennart Glad to hear it helped! If you think this solves your question, please consider marking it as the accepted answer so it can assist other users as well.Best regards, Isi
- 1 kudos
- 2172 Views
- 1 replies
- 0 kudos
Linking Workspace IDs to Names in Billing Schema
Hi everyone,We recently enabled UC and the Billing system table to monitor our usage and costs. We've successfully set up a dashboard to track these metrics for each workspace. The usage table includes the workspace_id, but I'm having trouble finding...
- 2172 Views
- 1 replies
- 0 kudos
- 0 kudos
I got this from their older version of the dashboard. dbdemos uc-04-system-tablesWhen everything is executed, go to your graph in the dashboard, click three dots in the top right, select in my case "View dataset:usage_overview" then paste/modify sql ...
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |