Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: How do I register a UDF that returns an array ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-30-2016 01:28 PM
I'm relatively new to Scala. In the past, I was able to do the following python:
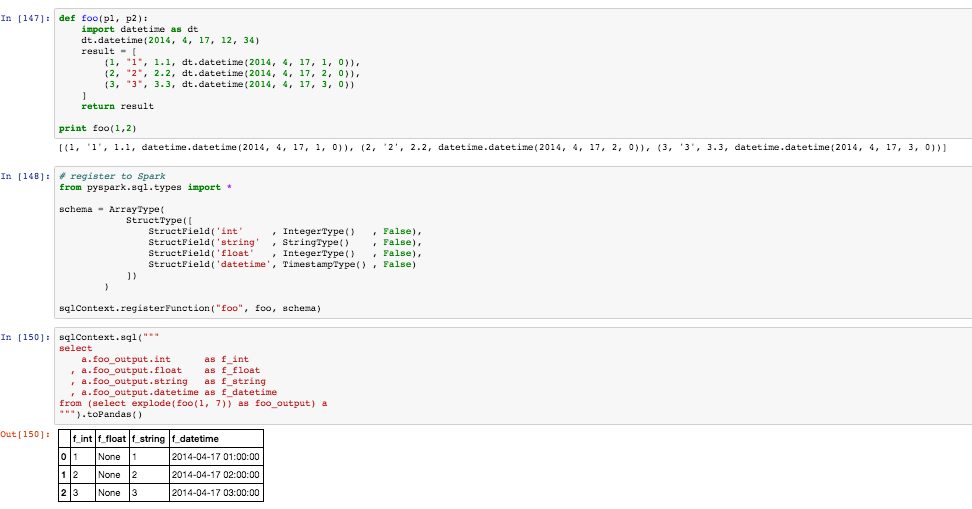
def foo(p1, p2):
import datetime as dt
dt.datetime(2014, 4, 17, 12, 34)
result = [
(1, "1", 1.1, dt.datetime(2014, 4, 17, 1, 0)),
(2, "2", 2.2, dt.datetime(2014, 4, 17, 2, 0)),
(3, "3", 3.3, dt.datetime(2014, 4, 17, 3, 0))
]
return resultNow I register it to a UDF:
from pyspark.sql.types import *
schema = ArrayType(
StructType([
StructField('int' , IntegerType() , False),
StructField('string' , StringType() , False),
StructField('float' , IntegerType() , False),
StructField('datetime', TimestampType() , False)
])
)
sqlContext.registerFunction("foo", foo, schema)
Finally, here is how I intend to use it:
sqlContext.sql("""
select
a.foo_output.int as f_int
, a.foo_output.float as f_float
, a.foo_output.string as f_string
, a.foo_output.datetime as f_datetime
from (select explode(foo(1, 7)) as foo_output) a
""").show()
This actual works in pyspark as shown above. See

I was not able to get the same thing to work in scala. Can anyone point me to the proper way to do this in scala/spark. When I tried to register the schema:
def foo(p1 :Integer, p2 :Integer)
: Array[Tuple4[Int, String, Float, Timestamp]] =
{
val result = Array(
(1, "1", 1.1f, new Timestamp(2014, 4, 17, 1, 0, 0, 0)),
(2, "2", 2.2f, new Timestamp(2014, 4, 17, 2, 0, 0, 0)),
(3, "3", 3.3f, new Timestamp(2014, 4, 17, 3, 0, 0, 0))
);
return result;
}
// register to Spark
val foo_schema = ArrayType(StructType(Array(
StructField("int" , IntegerType , false),
StructField("string" , StringType , false),
StructField("float" , FloatType , false),
StructField("datetime", TimestampType, false)
))
);
sql_context.udf.register("foo", foo _); I get a runtime error:
org.apache.spark.sql.AnalysisException: No such struct field int in _1, _2, _3, _4; line 2 pos 4
So, from the error message, it seems obvious that I didn't attach the schema properly and indeed in the above code, nowhere did I tell spark about it. So I tried to the following:
sql_context.udf.register("foo", foo _, foo_schema);
However, it gives me a compiler error:
[ERROR] /Users/rykelley/Development/rovi/IntegralReach-Main/ADW/rovi-master-schedule/src/main/scala/com/rovicorp/adw/RoviMasterSchedule/BuildRoviMasterSchedule.scala:247: error: overloaded method value register with alternatives:
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF22[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF21[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF20[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF19[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF18[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF17[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF16[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF15[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF14[_, _, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF13[_, _, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF12[_, _, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF11[_, _, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF10[_, _, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF9[_, _, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF8[_, _, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF7[_, _, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF6[_, _, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF5[_, _, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF4[_, _, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF3[_, _, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF2[_, _, _],returnType: org.apache.spark.sql.types.DataType)Unit <and>
[INFO] (name: String,f: org.apache.spark.sql.api.java.UDF1[_, _],returnType: org.apache.spark.sql.types.DataType)Unit
[INFO] cannot be applied to (String, (Integer, Integer) => Array[(Int, String, Float, java.sql.Timestamp)], org.apache.spark.sql.types.ArrayType)
Can someone point me in the right direction?
Note: using spark 1.6.1.
Thanks
Ryan


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-01-2016 09:57 AM
I'd recommend following the Databrick's guide to accomplish this:
I've imported this guide myself into my environment and was able to get a similar example working no problem.
7 REPLIES 7
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-01-2016 09:57 AM
I'd recommend following the Databrick's guide to accomplish this:
I've imported this guide myself into my environment and was able to get a similar example working no problem.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-01-2016 10:20 AM
That does not really answer my question since these examples do not have a case where the return type is an array of tuples. Can you share your solution?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-01-2016 11:26 AM
I found a satisfying solution. Instead of using a return type of Array[Typle4[...]], I used a case class to create a simple structure:
case class Result (
f_int : Int,
f_string : String,
f_float : Float,
f_ts : Timestamp
);
def foo2(p1 :Integer, p2 :Integer) : Array[Result] =
{
val result = Array(
Result(1, "1", 1.1f, new Timestamp(2014, 4, 17, 1, 0, 0, 0)),
Result(2, "2", 2.2f, new Timestamp(2014, 4, 17, 2, 0, 0, 0)),
Result(3, "3", 3.3f, new Timestamp(2014, 4, 17, 3, 0, 0, 0))
);
return result;
}
sqlContext.udf.register("foo2", foo2 _);
sqlContext.sql("""
select
a.foo_output.f_int as f_int
, a.foo_output.f_float as f_float
, a.foo_output.f_string as f_string
, a.foo_output.f_ts as f_datetime
from (select explode(foo2(1, 7)) as foo_output) a
""").show()
This seemed to give the desired output and is the same as pyspark.
I'm still curious as to how to explicitly return a array of tuples. The fact that I got it to work in pyspark lends evidence to the existence of a way to accomplish the same thing in scala/spark.
Any thoughts?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-06-2016 06:41 AM
Any response on this? The link provided doesn't answer the question.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-06-2016 02:32 AM
I'm assuming you already found your answer, but since this is the top result that comes up when googling this issue and it remains unanswered, I'll add my 2 cents.
As far as I know, all the elements in your ArrayType have to be of the same Type.
So for instance, you can register a simple function returning a list of strings with the following syntax:
sqlContext.udf.register("your_func_name", your_func_name, ArrayType(StringType()))I assume the reason your PySpark code works is because defininf the array elements as "StructTypes" provides a workaround for this restriction, which might not work the same in Scala.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-09-2017 08:18 AM
@kelleyrw might be worth mentioning that your code works well with Spark 2.0 (I've tried it with 2.0.2). However it's still not very well documented - as using Tuples is OK for the return type but not for the input type:
- For UDF output types, you should use plain Scala types (e.g. tuples) as the type of the array elements
- For UDF input types, arrays that contain tuples would actually have to be declared as
mutable.WrappedArray[Row]
So, if you want to manipulate the input array and return the result, you'll have to perform some conversion from Row into Tuples explicitly.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2017 05:40 PM
Hello,
Just in case, here is an example for proposed solution above:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions._
import org.apache.spark.sql.types._
val data = Seq(("A", Seq((3,4),(5,6),(7,10))), ("B", Seq((-1, 1)))).toDS
data.printSchema
root
|-- _1: string (nullable = true)
|-- _2: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- _1: integer (nullable = false)
| | |-- _2: integer (nullable = false)def fun(s: Seq[Row]): Seq[(Int, Int)] = {
s.filter(tuple => tuple.getInt(0) > 0)
.map(tuple => (tuple.getInt(0), tuple.getInt(1)))
}
val funUdf = udf(fun _)
data.select('_1, '_2, funUdf('_2) as "filtered").show(false)+---+----------------------+----------------------+
|_1 |_2 |filtered |
+---+----------------------+----------------------+
|A |[[3,4], [5,6], [7,10]]|[[3,4], [5,6], [7,10]]|
|B |[[-1,1]] |[] |
+---+----------------------+----------------------+Best regards,
Maxim Gekk
Announcements





{kind=link}
Related Content
- Registering Delta tables from external storage GCS , S3 , Azure Blob in Databricks Unity Catalog in Data Engineering
- Is there a Sample Java Program using Databricks Connect Library to query a table In the Free Editio? in Warehousing & Analytics
- Metric Views Window Period to Date not working in Warehousing & Analytics
- Connection reset error from Databricks notebook but works via curl (GCP) in Data Engineering
- Best practices for health monitoring in Administration & Architecture