- 2488 Views
- 1 replies
- 1 kudos
Error on pandas udf usage in databricks, sc.broadcasting random forest loaded from Kedro MLFlow Logger DataSet, cannot pickle '_thread.RLock' object
I'm trying to broadcast a Random forest (sklearn 1.2.0) recently loaded from mlflow, and using Pandas UDF to predict a model.However, the same code works perfectly on Spark 2.4 + our OnPrem cluster.I thought it was due to Spark 2.4 to 3 changes, an...
- 2488 Views
- 1 replies
- 1 kudos
- 2926 Views
- 5 replies
- 1 kudos
Latest Blog PostsJanuary 13 - 20 Did you get a chance to look at the most recent blog posts? Here are some happening content from the past week that i...
Latest Blog PostsJanuary 13 - 20Did you get a chance to look at the most recent blog posts? Here are some happening content from the past week that is worth the read. What’s New With SQL User-Defined Functions In this blog, we describe several enhanc...
- 2926 Views
- 5 replies
- 1 kudos
- 1 kudos
Thanks @Sujitha Ramamoorthy , for sharing with the community these are worth reading and insightful.
- 1 kudos
- 7227 Views
- 8 replies
- 3 kudos
com.amazonaws.services.s3.model.AmazonS3Exception: The bucket is in this region: *** when using S3 Select
Hello,I have a cluster running in us-east-1 region.I hava a Spark job loading data in a DataFrame using s3select format on a bucket in eu-west-1 region.Access and Secret keys are encoded in URI s3a://$AccessKey:$SecretKey@bucket/path/to/dirJob fails ...
- 7227 Views
- 8 replies
- 3 kudos
- 3 kudos
Hello,I tried your suggestion by setting up the peering connection between the 2 VPC but issue remains the same.The error message The bucket is in this region: .... please use this region to retry the requestmakes me think that the root cause is not ...
- 3 kudos
- 13997 Views
- 1 replies
- 1 kudos
Unity Catalog Pricing
Hi All, I would like to understand the pricing model of the Unity Catalog. Earlier I remember there was some mention of the data lineage and a few other features that will have a cost associated with it. If that's true, what other features cost us? W...
- 13997 Views
- 1 replies
- 1 kudos
- 1 kudos
Hi @Venkadeshwaran K ,All Unity Catalog features are provided at no charge to customers, provided they are using a Premium or Enterprise SKU.
- 1 kudos
- 4226 Views
- 3 replies
- 3 kudos
How to circumvent Py4JSecurityException for spark-nlp : Constructor public com.johnsnowlabs.nlp.***(java.lang.String) is not whitelisted.
Running into the following error on our company's cluster. py4j.security.Py4JSecurityException: Constructor public com.johnsnowlabs.nlp.DocumentAssembler(java.lang.String) is not whitelisted.For the following code(which is just tutorial code from the...
- 4226 Views
- 3 replies
- 3 kudos
- 3 kudos
Hi @Kenan Spruill Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Than...
- 3 kudos
- 2831 Views
- 3 replies
- 3 kudos
Is it possible to access online feature store (Cosmos DB) outside databricks?
We are building an machine learning application with feature store enabled. Once the model is built, we are trying to move the model artifacts and deploy it in azure ml as online endpoint. Does it possible to access the online store in azure ml endpo...
- 2831 Views
- 3 replies
- 3 kudos
- 3 kudos
if you want databricks to use the feature store, which is in Cosmos DB, yes, it is possible https://learn.microsoft.com/en-us/azure/databricks/machine-learning/feature-store/online-feature-storessuppose you want to consume a future store in Databrick...
- 3 kudos
- 4119 Views
- 7 replies
- 0 kudos
Databricks not able to create table in minio bucket
Trying to create table in minio bucket using databricks.spark.sql("create database if not exists minio_db_1 managed location 's3a://my-bucket/minio_db_1'");I am passing the s3 configurations using spark context.access_key = 'XXXX'secret_key = 'XXXXXX...
- 4119 Views
- 7 replies
- 0 kudos
- 0 kudos
MANAGED LOCATION is for Unity Catalog. Please check if you are under the unity catalog, not under hive metastore. Additionally, with Unity, you are not using sc._jsc.hadoopConfiguration() etc. but just register storage credentials and external locati...
- 0 kudos
- 1653 Views
- 1 replies
- 0 kudos
Weekly Release Notes Recap Here’s a quick recap of the latest release notes updates from the past one week. Databricks platform release notesJanuary 1...
Weekly Release Notes RecapHere’s a quick recap of the latest release notes updates from the past one week.Databricks platform release notesJanuary 13 - 19, 2023Cluster policies now support limiting the max number of clusters per userYou can now use c...
- 1653 Views
- 1 replies
- 0 kudos
- 3354 Views
- 3 replies
- 2 kudos
Cannot write Feature Table because of invalid access token
From a notebook I created a new feature store via:%sql CREATE DATABASE IF NOT EXISTS feature_store_ebp;Within that feature store I fill my table with:feature_store_name = "feature_store_ebp.table_1" try: fs.write_table( name=feature_stor...
- 3354 Views
- 3 replies
- 2 kudos
- 2 kudos
What kind of runtime machine (version) do you use to run this code?
- 2 kudos
- 2684 Views
- 2 replies
- 0 kudos
I need to access the json file in the github repo from the databricks notebookI have a repo integrated with Databricks workspace. When I run %sh pwd ...
I need to access the json file in the github repo from the databricks notebookI have a repo integrated with Databricks workspace. When I run %sh pwd it returns this path /Workspace/Repos/chris@myemail/Repo/folder/test.json. I'm not able to access the...
- 2684 Views
- 2 replies
- 0 kudos
- 8718 Views
- 6 replies
- 2 kudos
Solution for - "PythonException: 'ModuleNotFoundError: No module named 'spacy'
I am actually trying to extract the adjective and noun phrases from the text column in spark data frame for which I've written the udf and applying on cleaned text column. However, I am getting this error.from pyspark.sql.functions import udffrom pys...
- 8718 Views
- 6 replies
- 2 kudos
- 2 kudos
only init script will work here
- 2 kudos
- 1944 Views
- 2 replies
- 4 kudos
Implementation of best practices in authorization to a service application
we are working on authentication mechanism for our model service application using python framework fastAPI deployed on azure cloud, Need help on end to end auth mechanism(either through inbuild mechanism in python like jwt etc., or with azure).kindl...
- 1944 Views
- 2 replies
- 4 kudos
- 4 kudos
Could you please explain it a little more?For authentication, please refer: https://learn.microsoft.com/en-us/azure/databricks/dev-tools/api/latest/authenticationhttps://learn.microsoft.com/en-us/azure/databricks/security/security-overview-azure#--au...
- 4 kudos
- 3196 Views
- 2 replies
- 2 kudos
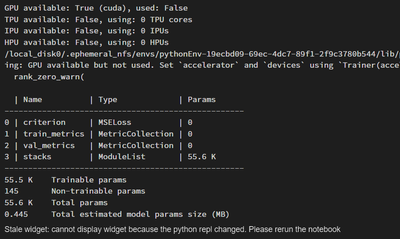
Number of epochs/epoch loss widget not visible while training the model
I am training a N-BEATS forecasting model using darts library. After I define all my hyper parameters and execute the code to fit my model and have set the ''verbose'' parameter to true according to the documentation to show the progress of the train...


- 3196 Views
- 2 replies
- 2 kudos
- 2 kudos
Hi @Mrinmoy Gupta, what happens when you detach the notebook from the cluster (and optionally clear the state) and then rerun the code? I've seen this happen once and it was a solved by re-running the code
- 2 kudos
- 3706 Views
- 1 replies
- 1 kudos
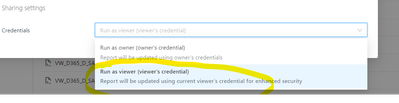
Permission errors.
I have some permission erros when I want to modify some sql queries in SQL module. We are two colleauge working on one project so we build da data model. Sometimes we need to correct each other and access the SQL code but unfortunelty we dont have a...
- 3706 Views
- 1 replies
- 1 kudos
- 1 kudos
you not worry here , give permission as a viewer only , or else they will use your creds there This doc will be helpful - https://docs.databricks.com/security/access-control/query-acl.htmlThanksAviral Bhardwaj
- 1 kudos
- 16614 Views
- 8 replies
- 0 kudos
Resolved! Inheritance model in Unity Catalog is not working as per documentation.
As per the documentation "Securable objects in Unity Catalog are hierarchical and privileges are inherited downward. The highest level object that privileges are inherited from is the catalog". Executed following statement "GRANT SELECT ON CATALOG uc...
- 16614 Views
- 8 replies
- 0 kudos
Join Us as a Local Community Builder!
Passionate about hosting events and connecting people? Help us grow a vibrant local community—sign up today to get started!
Sign Up Now-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
38 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
Devops
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
60 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
2 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
12 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »
| User | Count |
|---|---|
| 89 | |
| 39 | |
| 38 | |
| 25 | |
| 25 |