Hi!If I need to use many workers to distributes regular pandas, I would use a pandas_UDF. (having regular python crunching a slice of my data, on each node, and combining all results back to the driver node)Is there something equivalent for R?Thanks,
Hi Team,I am trying to implement automl in python for my timeseries forecast problem.But, I was facing below error during the model training:AttributeError: 'StanModel' object has no attribute 'fit_class'Due to the above error, the experiment failed ...
Hi @Prakash Thavamurugan Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from y...
from databricks import feature_storeI am trying to import feature_store but it is showing this error.ImportError: cannot import name 'feature_store' from 'databricks' (/databricks/python/lib/python3.8/site-packages/databricks/__init__.py)
Hello, I am very new with databricks and MLflow. I faced with the problem about running job. When the job is run, it usually failed and retried itself, so it incasesed running time, i.e., from normally 6 hrs to 12-18 hrs. From the error log, it shows...
Hey there @Tanawat Benchasirirot Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hea...
I'm in a Data Science Bootcamp, and the final case study includes data preprocessing (done), using a linear regression model on the data, then porting to SQL for visualization. The model build uses custom python code provided as part of the exercise....
ImportError: cannot import name '_MIN_SKLEARN_VERSION' from 'mlflow.sklearn.utils' (/databricks/python/lib/python3.8/site-packages/mlflow/sklearn/utils.py)
Hi @Sameer Gupta Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thank...
Hi @Shawn Feng Does @Atanu Sarkar response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly?We'd love to hear from you.Thanks!
Hi,I can train, registered a ML Model in my Datbricks Workspace.Then, to deploy it on AKS, I need to register the model in Azure ML, and then, deploy to AKS.Is it possible to skip the Azure ML step?I would like to deploy directly into my AKS instance...
Hi, Thanks for reaching out to Databricks. Registering a model can be done, and it is not mentioned if it is optional or not in Microsoft documents. Reference : https://docs.microsoft.com/en-gb/azure/databricks/applications/mlflow/models#register-mod...
I am trying to distribute hyperparameter tuning using hyperopt on a tensorflow.keras model. I am using sparkTrials in my fmin:spark_trials = SparkTrials(parallelism=4)...best_hyperparam = fmin(fn=CNN_HOF, space=space, ...
This can happen when you try to serialize a keras model with an unserializable layer. What does your model look like? Also what is in that search space variable? What are you trying to optimize on?
I have saved a keras model in some directories in dbfs to load and retrain that with more data, etc. The problem is that when cluster stops and restarts, seems those directories and model are no longer available there and it starts training a new mod...
Hi All, We're just started to look at the feature store capabilities of Databricks. Our first attempt to create a feature table has resulted in very slow write. To avoid the time incurred by the feature functions I generated a dataframe with same...
Hi @Ashley Betts Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thank...
I'm using Azure Data Factory to create pipeline of Databricks notebooks, something like this:[Notebook 1 - data pre-processing ] -> [Notebook 2 - model training ] -> [Notebook 3 - performance evaluation].Can I write some config file, that would allow...
I understand that, in your case, auto-scaling will take too much time.The simplest option is to use a different cluster for another notebook (and be sure that the previous cluster is terminated instantly).Another option is to use REST API 2.0/cluster...
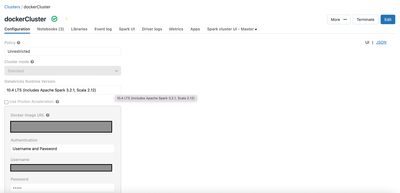
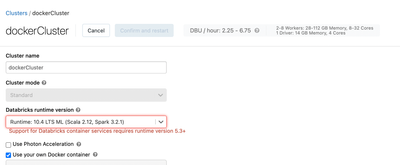
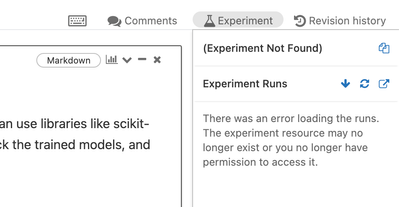
Hi! So I used this MLFlow experiment I found from the databricks website: https://docs.databricks.com/_static/notebooks/machine-learning-with-unity-catalog.htmlAnd I created this cluster using a custom Docker image I created myself: Usually when I c...
I could not paste the code here because of the some word not allowed, so I have to paste it elsewhere.Below is OK:https://justpaste.it/8xcr9But below gets stuck:https://justpaste.it/8nydtand it keeps looping and running...
Hey @THIAM HUAT TAN Hope all is well! Just wanted to check in if you were able to resolve your issue, and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you....
Hello, I am training a logistic regression on text with the help of an tf-idf vectorizer.This is done with MLflow and sklearn in databricks.The model itself is trained successfully in databricks and it is possible to accomplish predictions within the...