- 3747 Views
- 4 replies
- 1 kudos
Unable to access python variables in-between shells in same notebook
Unable to access Python variables in-between shells in the same notebook even if the entire code is written in Python. Getting error that unable to identify variable in the new cell
- 3747 Views
- 4 replies
- 1 kudos
- 1 kudos
Hi, thanks for your message. Can you sent a screenshot of your notebook maybe?This makes it hard to debug what could be the cause of it?Also which runtime are you using, this could might be the issue. With my experience loading the pandas library sho...
- 1 kudos
- 7794 Views
- 4 replies
- 0 kudos
Not able to log xgboost model to mlflow
I have been trying to log mlflow model but seems to be not working. It logs only the last(which is also the worst run).#-------------------------------------------------------13.0 ML XGBOost------------------------------------------------------------...
- 7794 Views
- 4 replies
- 0 kudos
- 0 kudos
@Kumaran Ran this code, but any specific log that I should be looking for?
- 0 kudos
- 1899 Views
- 1 replies
- 0 kudos
MlflowException: Unsupported Databricks profile key prefix: ''. Key prefixes cannot be empty.
I am trying to fetch data from mlflow model registry in Databricks and to use it in my local notebook. But I don't find any resource in internet to do so. I want to configure my mlflow in such a way i can fetch model registry values from databricks w...
- 1899 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @AnnamalaiVR,Thank you for posting the question in Databricks Community.In your Python code, import the MLflow library and create a client object to access your Model Registry. %pythonimport mlflow# Set the Databricks tracking URIdatabricks_host =...
- 0 kudos
- 10612 Views
- 2 replies
- 2 kudos
Resolved! Differences between Feature Store and Unity Catalog
Our small team has just finished the data preparation phase of our project and started data analysis in Databricks. As we go deeper into this field, we're trying to understand the distinctions and appropriate uses for a Feature Store versus a Unity C...
- 10612 Views
- 2 replies
- 2 kudos
- 2 kudos
Hi @Northp Good day!1.) A Feature Store is a centralized repository that enables data scientists to find and share features, ensuring that the same code used to compute the feature values is used for model training and inference. It is particularly...
- 2 kudos
- 6133 Views
- 4 replies
- 8 kudos
Azure - Databricks - account storage gen 2
Hello Every one, i am really new to databricks, just passed my apache developer certification on it.i also have a certification on data engineering with Azure.some fancy words here but i only started doing real deep work on them as i started a person...
- 6133 Views
- 4 replies
- 8 kudos
- 8 kudos
Hi,If we go by the error , Invalid configuration value detected for fs.azure.account.keyStorage account access key to access data using the abfssprotocol cannot be used. Please refer this https://learn.microsoft.com/en-us/azure/databricks/storage/azu...
- 8 kudos
- 6605 Views
- 6 replies
- 1 kudos
CUDA out of memory
I am trying out the new Meta LLama2 model.Following the databricks provided notebook example: https://github.com/databricks/databricks-ml-examples/blob/master/llm-models/llamav2/llamav2-13b/01_load_inference.py I keep getting CUDA out of memory. My G...
- 6605 Views
- 6 replies
- 1 kudos
- 1 kudos
Hi @Kumaran Hope you are well. Just wanted to see if you were able to find an answer to your question and would you like to mark an answer as best? It would be really helpful for the other members too. Cheers!
- 1 kudos
- 4674 Views
- 3 replies
- 0 kudos
- 4674 Views
- 3 replies
- 0 kudos
- 0 kudos
You can take all the Databricks exams as many times as you want, but you have to pay a fee each time you take the exam.
- 0 kudos
- 10951 Views
- 2 replies
- 1 kudos
Running test inference on Llama-2-70B-chat-GPTQ… are C++ libraries installed correctly?
Hi all,I was following the hugging face model https://huggingface.co/TheBloke/Llama-2-70B-chat-GPTQ, which points to use Exllama (https://github.com/turboderp/exllama/), which has 4 bit quantization.Running on a A10-Single-GPU-64GB,I've cloned the Ex...
- 10951 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @Kumaran,Thanks so much for the quick reply. When I run the script with !bash install_cusparse.shIt runs for a bit, but ultimately encounters an error. When I run !ls -l, i dont even see a data-mle directory in dbfshere is the full output from run...
- 1 kudos
- 2352 Views
- 2 replies
- 1 kudos
E-mail notification on failure run with DBX deployment
I am deploying workflow to Databricks using DBX. Here I want to add that when the workflow runs and if it fails I will get an e-mail on my_email@email.com. I have included an example workflow. deployments: - name: my_workflow ... # Other wo...
- 2352 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @akc,Thank you for posting your question in the Databricks community.Please refer to this documentation for the email notification.
- 1 kudos
- 8684 Views
- 1 replies
- 0 kudos
Cannot re-initialize CUDA in forked subprocess.
This is the error I am getting :"RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method". I am using 13.0nc12s_v3 Cluster.I used this one :"import torch.multiprocessing as...
- 8684 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @phdykd,Thank you for posting your question in the Databricks community.One approach is to include the start_method="fork" parameter in the spawn function call as follows: mp.spawn(*prev_args, start_method="fork"). Although this will work, it migh...
- 0 kudos
- 1843 Views
- 0 replies
- 0 kudos
Unable to Infer Spark ML Pipeline model when built using Custom Preprocessing Stages
We are trying to build an internal use case based on PySpark. The data we have requires a lot of pre-processing. Hence, to cater to that we have used custom Spark ML pipeline stages as some of the transformations that need to be done on our data aren...
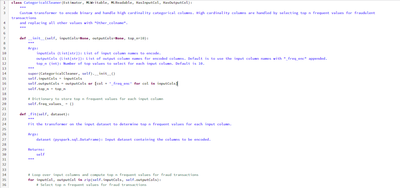
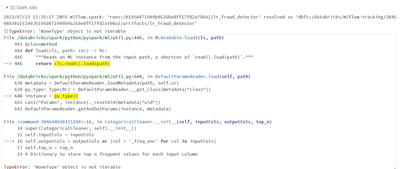
- 1843 Views
- 0 replies
- 0 kudos
- 3889 Views
- 4 replies
- 4 kudos
Resolved! Pyspark streaming optimization we need to focus on
What optimization we should focus on?
- 3889 Views
- 4 replies
- 4 kudos
- 4 kudos
@YanhDong_68817 This document is one of the good places to start evaluating our streaming pipeline - https://docs.databricks.com/structured-streaming/production.html
- 4 kudos
- 3356 Views
- 2 replies
- 2 kudos
Resolved! sparkxgbregressor and RandomForestRegressor not able to deploy for inferencing
I have been trying to deploy spark ML Models from the experiement page via UI, the deployment gets aborted after a long run, any particular reason for why this might be happening? I have also taken care of dependencies still it is failing.Dependency ...
- 3356 Views
- 2 replies
- 2 kudos
- 2 kudos
@Kumaran Thanks for the reply kumaram The deployment was finally successful for Random Forest algorithm, failing for sparkxgbregressor.Sharing code snippet:from xgboost.spark import SparkXGBRegressor vec_assembler = VectorAssembler(inputCols=train_df...
- 2 kudos
- 1590 Views
- 2 replies
- 0 kudos
Databricks machine learning associate certificate test was suspended
Hello, I was doing this test on July 5th at 1:45pm (Los Angelas) time, and the test screen complained about my eyes not looking at screen for 5 seconds (when my room got really hot and I picked up a fan on the side), then the test was suspended. Can ...
- 1590 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @F5 ,Thank you for posting question in Databricks community.I can see that support request #00342886 has been already handled, Please let us know if you need more help on this.
- 0 kudos
- 3956 Views
- 5 replies
- 0 kudos
Fine Tuning Dolly
Hi Community, could you guys share your experience fine tuning Dolly? Thanks, Kevin K.
- 3956 Views
- 5 replies
- 0 kudos
- 0 kudos
Hi @KevinKnights,Thank you for your question in the Databricks community.I understand that you are looking for documentation on how to fine-tune the Dolly model. Please refer to this documentation on how to fine-tune the model, and let us know if it ...
- 0 kudos
-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
44 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
Devops
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
61 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
3 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
27 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »
| User | Count |
|---|---|
| 90 | |
| 40 | |
| 38 | |
| 28 | |
| 25 |