Is it possible to use a stratified sampling strategy for the train/test/validate splits that the automl library does? We are working in a context where we need to segregate certain groups from the training and test sets to see how our models general...
HI @Jared Webb Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers yo...
I have been trying to start a cluster using DCS with GPU containers (https://github.com/databricks/containers/tree/master/ubuntu/gpu), but was only successful with Databricks Runtime 10.4 LTS and lower. With Databricks Runtime 11.3 LTS and higher, I ...
Hey community membersI am new to Databricks and was building a simple DLT pipleine that loads data from S3 and runs an Isolation forest prediction to detect anomalies. The model has been stored in Model Registry. Here's the code for the pipeline:@dlt...
Hi @Mukul Degweker Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Tha...
Monthly Community Q&A: Ask the Experts! We're excited to announce our first monthly Community Q&A session! This is your chance to ask questions, seek advice, and gain insights from our team of Data Science and AI experts.Whether you're curious abou...
Hi! @Kaniz Fatma Thanks for the answer and nice explanation. As per my expertise, even embedded systems design with IoT work in a wide range of areas. It just only requires an AI gateway system.
@Saurabh Singh This is well documented here:https://www.databricks.com/blog/2022/06/22/architecting-mlops-on-the-lakehouse.htmlPlease see: Reference architecture for MLOpsFurther refrences: Refer to The Big Book of MLOps for more discussion of the a...
Hello Everyone,I am thrilled to announce that we have our 5th winner for the raffle contest - @Emilia. Please join me in congratulating her on this remarkable achievement!Your dedication and hard work have paid off, and we are delighted to have you ...
We are using Delta Live Tables for running ingestion pipelines and have come across the two options for the autoloader "file notification" vs "directory listing" this is reflected in the option cloudFiles.useIncrementalListing. We are wondering what ...
@Bennett Lambert :The choice between using "file notification" vs "directory listing" for the autoloader in Delta Live Tables depends on your specific use case and requirements. Here are some general guidelines:Use file notification if you need real...
Hello, My problem:I'm trying to run a pytorch code which include multiprocessing on databricks and mt code is crashing with the note: Fatal error: The Python kernel is unresponsive.The Python process exited with exit code 134 (SIGABRT: Aborted).Closi...
This is because multiprocessing will not use the distributed framework of spark/databricks.When you use that, your code will run on the driver only and the workers are not doing anything.More info here.So you should use a spark-enabled ML library, li...
***Understanding Databricks Machine Learning Workspace - 1***Databricks Machine Learning helps you simplify and standardize your ML development processes. It is helpful to :Train models either manually or with AutoML.Track training parameters and mo...
I saved an xgboost boost model in filetstore as a pkl file.I call the model by the commands belowmodel = pickle.load(open('/.../model.pkl', 'rb'))model.predict_proba(df[features])The model has been running for sometime with the above commands but I n...
Hi @Michael Okelola Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answe...
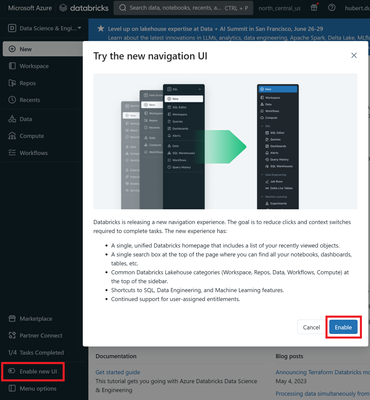
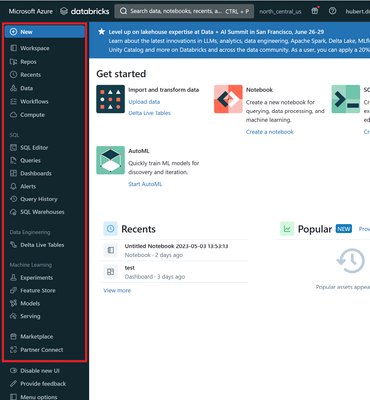
Introducing the new databricks UI: a sleek and intuitive data science and engineering interface. Don’t miss this opportunity to experience the power and simplicity of Databricks. Try it out today!
Hello Everyone,I am thrilled to announce that we have our 3rd winner for the raffle contest - @Jogeswara. Please join me in congratulating him on this remarkable achievement!Jogesswara, your dedication and hard work have paid off, and we are deligh...
Hi, is there an officially recommended book for the machine learning associate/professional certification? Or any sort of study guide or even third party course? I really struggle to find some study material for this activity.
Note: the following guide is primarily for Python users. For other languages, please view the following links: • Table batch reads and writes • Create a table in SQL • Visualizing data with DBSQLThis step-by-step guide will get your data...