- 2774 Views
- 1 replies
- 6 kudos
docs.databricks.com
New unified Databricks navigationDatabricks plans to enable the new navigation experience (Public Preview) by default for all users. You’ll be able to opt out by clicking Disable new UI in the sidebar.The goal of the new experience is to reduce click...
- 2774 Views
- 1 replies
- 6 kudos
- 6 kudos
Hi @Priyadarshini G Thank you for providing accurate and valuable information.Best Regards
- 6 kudos
- 3730 Views
- 4 replies
- 3 kudos
dbx execute cluster issue
I am facing issue with cluster not being able to run the updated code using dbx execute command. Any changes I make to the code is not reflected in the execution until I restart the cluster. I am using a photon enable cluster with Standard_D4s_v5 as ...
- 3730 Views
- 4 replies
- 3 kudos
- 3 kudos
Hi @Tarique Anwar Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Than...
- 3 kudos
- 2851 Views
- 3 replies
- 3 kudos
Can someone help my academy account switching from partner to customer?
Hi, Today I accidentally created my account in partner-academy.I created my academy account in partner-academy with my company email, then I realized I can't create account with same email in customer-academy which is correct place I should have crea...
- 2851 Views
- 3 replies
- 3 kudos
- 3 kudos
Hi @Haekyung Won Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers ...
- 3 kudos
- 1503 Views
- 1 replies
- 1 kudos
Is it possible to start Databricks AutoML experiment remotely? (Azure Databricks)
Currently I am using Azure Machine Learning Studio for my work, and would like to compare performance of Azure and Databricks automl algorithms. Is it possible to write a notebook in Azure to start the automl algorithm in Databricks? My data is found...
- 1503 Views
- 1 replies
- 1 kudos
- 1 kudos
Hi @Csaba Aranyi Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question. Thanks.
- 1 kudos
- 1511 Views
- 1 replies
- 2 kudos
How do I move the template files into my own repo when cloning the MLflow recipes templates into Databricks?
Here https://mlflow.org/docs/latest/recipes.html#model-development-workflow, there are directions to add the repo. Is this best practice in Databricks? I tried exporting the repo code (inside of a Databricks notebook).. My DBC export was successful. ...
- 1511 Views
- 1 replies
- 2 kudos
- 2 kudos
Hi @Stephanie Rivera Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question. Thanks.
- 2 kudos
- 1835 Views
- 1 replies
- 2 kudos
AWS Databricks - Distributed ML Models in Sagameker and Databricks
While using Databricks on AWS, What will be impact if few ML models are build using Sagemaker pipelines, whereas other models build on databricks ML itself ?Any other impact apart from infra maintainance cost ?Are there any prefered tool that can eas...
- 1835 Views
- 1 replies
- 2 kudos
- 2 kudos
Hi @Saurabh Singh Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question. Thanks.
- 2 kudos
- 19187 Views
- 5 replies
- 6 kudos
Resolved! Fix Hanging Task in Databricks
I am applying a pandas UDF to a grouped dataframe in databricks. When I do this, a couple tasks hang forever, while the rest complete quickly.I start by repartitioning my dataset so that each group is in one partition:group_factors = ['a','b','c'] #m...
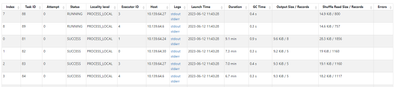


- 19187 Views
- 5 replies
- 6 kudos
- 6 kudos
Thank you Suteja. I had watched the resources and had never reached capacity for any. The data was evenly distributed across partitions and groups as well. I did end up taking your advice in (1). I set a timer and killed the process if the group took...
- 6 kudos
- 6427 Views
- 3 replies
- 5 kudos
Resolved! Difference between MLFlow recipes and projects?
MLFlow projects are described asAn MLflow Project is a format for packaging data science code in a reusable and reproducible way, based primarily on conventions. In addition, the Projects component includes an API and command-line tools for running p...
- 6427 Views
- 3 replies
- 5 kudos
- 5 kudos
Thanks for the answer @Priyadarshini G . Although a project has a pre-defined folder structure and standard files, it also "... includes an API and command-line tools for running projects, making it possible to chain together projects into workflows...
- 5 kudos
- 6656 Views
- 4 replies
- 3 kudos
Resolved! How to enforce schema with Autoloader?
I have a number of csv files that I am working to ingest using autoloader. There is an ID field that I want to require to be a STRING, but using SchemaHints is not working and is instead setting as an INT.The first few csv files have just integer va...
- 6656 Views
- 4 replies
- 3 kudos
- 3 kudos
Hi @Jennette Shepard We haven't heard from you since the last response from @Suteja Kanuri . Kindly share the information with us, and in return, we will provide you with the necessary solution.Thanks and Regards
- 3 kudos
- 4786 Views
- 4 replies
- 5 kudos
Resolved! Authenticating gitlab with databricks via username & password?
Currently we have azure databricks and gitlab in our project, for integrating with code repository we have only gitlab, integrating with personal access token is possible,But it flagged out as potential risk of personal access token exposure, wanted...
- 4786 Views
- 4 replies
- 5 kudos
- 5 kudos
Thank you folks,currently only way to integrate with gitlab is only with Personal Access Token,There is not way to intergrate gitlab via password, as per our security recommendation, we need to have additional mechanism to integrate as exposure of Pe...
- 5 kudos
- 5813 Views
- 3 replies
- 3 kudos
Resolved! Distributed training on building object detection model on PyTorch and PySpark.
I'm currently immersed in a project where I'm leveraging PyTorch to develop an object detection model using satellite imagery. My immediate objective is to perform distributed training on this model using PySpark. While I have found several tutorials...
- 5813 Views
- 3 replies
- 3 kudos
- 3 kudos
Hi @Jaeseon Song Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers ...
- 3 kudos
- 4452 Views
- 2 replies
- 1 kudos
Resolved! Docker image with libraries + MLFlow Experiments
Hi everybody,I have a scenario where we have multiple teams working with Python and R, and this teams uses a lot of different libraries. Because of this dozen of libraries, the cluster start took much time. Then I created a Docker image, where I can ...
- 4452 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @Fabio Simoes Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers ...
- 1 kudos
- 7897 Views
- 2 replies
- 2 kudos
Resolved! "Photon ran out of memory" while when trying to get the unique Id from sql query
I am trying to get all unique id from sql query and I always run out of memoryselect concat_ws(';',view.MATNR,view.WERKS) from hive_metastore.dqaas.temp_view as view join hive_metastore.dqaas.t_dqaas_marc as marc on marc.MATNR = view.MATNR where view...
- 7897 Views
- 2 replies
- 2 kudos
- 2 kudos
Hi @Anil Kumar Chauhan We haven't heard from you since the last response from @Werner Stinckens . Kindly share the information with us, and in return, we will provide you with the necessary solution.Thanks and Regards
- 2 kudos
- 6928 Views
- 4 replies
- 8 kudos
Resolved! Issue in Converting Pyspark Dataframe to dictionary
I have 3 questions listed below.Q1. I need to install third party library in Unity Catalog enabled shared cluster. But I am not able to install. It is not accepting dbfs path dbfs:/FileStore/jars/Q2. I have a requirement to load the data to salesforc...
- 6928 Views
- 4 replies
- 8 kudos
- 8 kudos
Hi @SK ASIF ALI We haven't heard from you since the last response from @werners (Customer) . Kindly share the information with us, and in return, we will provide you with the necessary solution.Thanks and Regards
- 8 kudos
- 3322 Views
- 2 replies
- 0 kudos
Running Keras model training with HorovodRunner works until the training function is exited ("The MPI_Query_thread() function was called after MPI_FINALIZE was invoked.")
I am running training of a Keras/Tensorflow deep learning model on a cluster of (for now) 2 workers and 1 driver (T4 GPU, 28GB, 4 core) using the Databricks provided HorovodRunner. It all seems to go well and the performance scales quite nicely over ...
- 3322 Views
- 2 replies
- 0 kudos
- 0 kudos
I personally suspect it's your callbacks. Can you remove all those state callbacks and see if that is it?
- 0 kudos
-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
44 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
Devops
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
61 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
3 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
27 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »
| User | Count |
|---|---|
| 90 | |
| 40 | |
| 38 | |
| 28 | |
| 25 |