We are facing this issue when accessing Features page. Our workspace is on AWS, ap-southeast-1.I think this is related to new feature for online tables and serverless. Is it because of online tables are not available yet in our region? If it not avai...
Hi @MinThuraZaw, I understand the issue you’re facing.
Let’s break it down:
Online Tables:
Online Tables are a new feature in Databricks that allows you to create read-only copies of Delta tables optimized for online access. These tables are full...
Hi @amal15, The error message you’re encountering, “XGBoostEstimator is not a member of package ml.dmlc.xgboost4j.scala.spark,” indicates that the XGBoostEstimator class is not being recognized within the specified package.
Check Dependencies:
E...
I have a naive Bayes ML model that takes call attributes and predicts if the caller is going to abandon the call while they are on hold waiting to speak to an agent. The model lives in Databricks ML flow, I have it registered. What I need to do is ex...
Hi @chrisf_sts,
Naive Bayes Model Overview: Naive Bayes is a probabilistic machine learning algorithm based on Bayes’ Theorem. It’s commonly used for classification tasks, such as spam filtering, document classification, and sentiment prediction....
Hello experts,We would like to create a UDF function with input parameter a table_name. Please check the below simple example:CREATE OR REPLACE FUNCTION F_NAME(v_table_name STRING, v_w...
Hello everyone,I have an Azure Databricks subscription with my company, and I want to use external LLMs in databricks, like claude-3 or gemini. I managed to create a serving endpoint for Anthropic and I am able to use claude 3.But I want to use a Gem...
Hi @Leo69, It seems you’re encountering an issue while trying to use the Gemini model through Databricks.
Let’s troubleshoot this together!
First, let’s review some important information about external models in Databricks Model Serving. External...
Hey,I'm composing an architecture within the usage of Model Serving Endpoints and one of the needs that we're aiming to resolve is Shadow Deployment.Currently, it seems that the traffic configurations available in model serving do not allow this type...
Hi @ryojikn, Shadow deployment is a valuable strategy for testing and validating changes in a production environment without impacting live traffic.
Let’s explore some approaches and resources related to shadow deployments:
Shadow Deployments:
Wh...
I am looking for the more detailed resources comparing RAG to fine-tuning methods in AI models to processing text data with LLM in laymen notes. I have found one resource but looking for the more detailed view https://www.softwebsolutions.com/resour...
Hi @kapwilson, It seems you’re encountering an issue with using archive files in your Spark application submitted as a Jar task.
Archive Files in Spark Applications: When submitting Spark applications, you can include additional files (such as Pyt...
Have been running into an issue when running a pymc-marketing model in a Databricks notebook. The cell that fits the model gets hung up and the progress bar stops moving, however the code completes and dumps all needed output into a folder. After the...
Hi @tim-mcwilliams,
It sounds like you’re encountering a situation where the notebook cell appears to hang while running a pymc-marketing model in Databricks, but the code was eventually completed successfully.
Let’s explore some potential reasons...
Hello,I'm interested in accessing several .mdb Access files stored in either Azure Data Lake Storage (ADLS) or the Databricks File System using Python. Could you provide guidance on how to accomplish this? It would be immensely helpful if you could a...
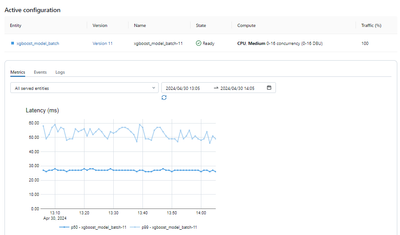
Hi, For the model serving latency graph what is p50 and p99? I only have one model i am serving on this endpoing so im surprised to see two models being tracked
Hello, I'm having problems trying to run my retraining notebook for a spacy model. The notebook creates a shell file with the following lines of code: cmd = f'''
awk '{{sub("source = ","source = /dbfs/FileStore/{dbfs_folder}/textcat/categories...
Hi @AndersenHuang,
Thank you for contacting Databricks community support.
The error message you're encountering suggests that there's a permission issue when trying to copy the files. It's possible that the permissions for the directory /dbfs/FileSto...
Hello,I'm trying to create and query a vector searc index like in this example : How to create and query a Vector Search index | Databricks on AWS on a databricks on azure. I have a cluster ina private network so i need to install the suggested lib ...
Hi I'm have succesfully registered my model using the feature engineering client with the following codes:with mlflow.start_run():
# Calculate the ratio of negative class samples to positive class samples
ratio = (len(y_train) - y_train.sum()...
Hello @Edna
Thank you for contacting Databricks community support.
MLflow allows you to save models using different "flavors," which are essentially different ways of serializing and deserializing models. When you specify flavor=mlflow.sklearn, you'...
Hello, I am trying to replicate this motebook in my environment: mlflow-end-to-end-example - Databricks However, I am getting the following error when I run "import mlflow": "TypeError: bases must be types"How can I solve this issue? Thank you, Tanji...
Hello @tanjil
Thank you for contacting databricks community support. Could you check what version of protobuf you have?
If you are using 10.4 ML cluster, the MLflow 1.x is not compatible with protobuf 4.x. The default version of protobuf in MLR 10...