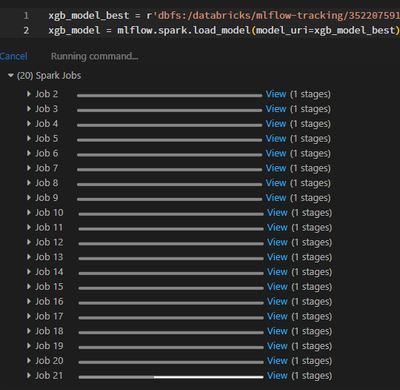
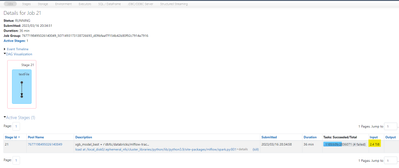
When loading an xgboost model from mlflow following the provided instructions in Databricks hosted MLflow the input sizes I am showing on the job are over 1 TB. Is anyone else using an xgboost.spark model and noticing the same behavior? Below are som...
while registering model I am getting error: AssertionError:I am getting error while running the code with workflow if I running code individually with notebook then its running fine. below is the code : fe = FeatureEngineeringClient() ...
Hello! I have code to use an API supplied in the energitdso package (This is the repository https://pypi.org/project/enerbitdso/). I changed the code adapting it to AZURE DATABRICKS in python, but although there is a connection with the API, it does ...
The owner of the package updated it to use the time out as a parameter of up to 20 seconds and updated a dependent package in DataBricks, with the above the problem was solved
When implementing the managed VectorSearch, what is the preferred way to implement row based access control? I see that you can use the filter API during a query, so simple filters using a certain column may work, but what if all the security informa...
getting this error when trying to setup the get-started-with-databricks-for-machine-learning LAB . Unity catalog is enabled. Validating the locally installed datasets: | listing local files...(0 seconds) | validation completed...(0 seconds total) C...
It looks like you don't have the CREATE CATALOG privilege on the metastore you're trying to create the catalog in:
Privilege types by securable object in Unity Catalog
Hello, I'm having problems trying to run my retraining notebook for a spacy model. The notebook creates a shell file with the following lines of code: cmd = f'''
awk '{{sub("source = ","source = /dbfs/FileStore/{dbfs_folder}/textcat/categories...
Hello Databricks Community,I am currently facing a challenge in configuring a cluster for training machine learning models on a dataset consisting of approximately a billion rows and 40 features. Given the volume of data, I want to ensure that the cl...
Hi @moh3th1 ,
Machine Selection:
Memory (RAM): Having sufficient memory is essential for large datasets. Ensure that your machine type has enough RAM to accommodate your data.CPU: CPU power impacts data processing speed. Consider CPUs with multiple...
Community Edition Login Issues
Below is a list of troubleshooting steps for failing to login with email/password at community.cloud.databricks.com:
Troubleshooting Tips
If this is your first time logging in, ensure that you did indeed sign u...
I am trying to serve a pyspark model using an endpoint. I was able to load and register the model normally. I could also load that model and perform inference but while serving the model, I am getting the following error: [94fffqts54] ERROR StatusLog...
Hi @Shreyash, It looks like your code is encountering a java.lang.ClassNotFoundException for the com.johnsnowlabs.nlp.DocumentAssembler class while serving your PySpark model. This error occurs when the required class is not found in the classpath.
...
Hi @amal15, The error message you’re encountering, “XGBoostEstimator is not a member of package ml.dmlc.xgboost4j.scala.spark,” indicates that the XGBoostEstimator class is not being recognized within the specified package.
Check Dependencie...
Hello, I am training a SparkXGBRegressor model. It runs without errors if the complexity is low, however when I increase the max_depth and/or num_parallel_tree parameters, I get an error. I checked the cluster metrics during training and it doesn't l...
Hi @e6exghu8,
Ensure that your cluster has sufficient memory to handle the increased complexity (higher max_depth and num_parallel_tree).Check the memory configuration for your Spark executors. You might need to allocate more memory to each executor...
I'm trying to delete rows from a table with the same date or id as records in another table. I'm using the below query and get the error 'Multi-column In predicates are not supported in the DELETE condition'. delete from cost_model.cm_dispatch_consol...
I am following along with this notebook found from this article. I am attempting to fine tune the model with a single node and multiple GPUs, so I run everything up to the "Run Local Training" section, but from there I skip to "Run distributed traini...
how i can import : import com.microsoft.ml.spark.{LightGBMClassifier,LightGBMClassificationModel}import ml.dmlc.xgboost4j.scala.spark.{XGBoostEstimator, XGBoostClassificationModel} projet spark & scala in databricks
XGBoostEstimator is not a member of package ml.dmlc.xgboost4j.scala.spark ?How can I resolve this error?with maven : ml.dmlc:xgboost4j-spark_2.12:2.0.3
I have a naive Bayes ML model that takes call attributes and predicts if the caller is going to abandon the call while they are on hold waiting to speak to an agent. The model lives in Databricks ML flow, I have it registered. What I need to do is ex...