- 4601 Views
- 3 replies
- 1 kudos
Gemini though Mosaic Gateway
I am trying to configure the Gemini Vertex API in Databricks. In simple Python code, everything works fine, which indicates that I have correctly set up the API and credentials. Error message: {"error_code":"INVALID_PARAMETER_VALUE","message":"INVALI...
- 4601 Views
- 3 replies
- 1 kudos
- 1 kudos
With support from a helpful Databricks employee, we found out that the problem was that the `private_key` / `private_key_plaintext` field needs to be the entire JSON object that GCP creates for the service account not just the private key string from...
- 1 kudos
- 937 Views
- 1 replies
- 0 kudos
unable to Publish Notebook
Hi,I am unable to publish Notebook from my workspace in community editionIt just give me blank error message
- 937 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @Saty1 Publishing a notebook in Databricks Community Edition can sometimes encounter issues due to various reasons, such as browser compatibility, network issues, or limitations within the Community Edition itself. Here are some steps you can take...
- 0 kudos
- 1671 Views
- 2 replies
- 0 kudos
Unable to convert R dataframe to spark dataframe
Hi All, Does anyone knows how to convert R dataframe to spark dataframe to Pandas dataframe? I wanted to get a Pandas dataframe ultimately but I guess I need to convert to spark first. I've been using this sparklyr library but my code did not work. T...
- 1671 Views
- 2 replies
- 0 kudos
- 0 kudos
Hello @Paddy_chu, Here's an updated version of the R code: %r library(sparklyr) library(SparkR) sc <- spark_connect(method = "databricks") matched_rdf <- psm_tbl %>% select(c(code_treat, code_control)) %>% data.frame() # Write the R dataframe t...
- 0 kudos
- 12493 Views
- 4 replies
- 2 kudos
MetadataChangedException Exception in databricks
Reading around 20 text files from ADLS, doing some transformations, and after that these files are written back to ADLS as a single delta file (all operations are in parallel through the thread pool). Here from 20 threads, it is writing to a single f...
- 12493 Views
- 4 replies
- 2 kudos
- 2 kudos
How can we import the exception "MetadataChangedException"?Or does Databricks recommend to catch / except Exception and parse the string?
- 2 kudos
- 11627 Views
- 4 replies
- 1 kudos
Permission denied: Lightning Logs
I'm doing parameter tuning for a NeuralProphet model (you can see in the image the parameters and code for training)When I try to parallelize the training, it gives me Permission Error.Why can't I access the folder '/databricks/spark/work/*'? Do I ne...
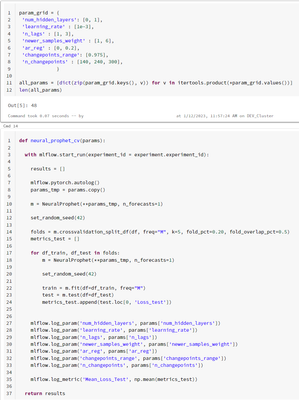
- 11627 Views
- 4 replies
- 1 kudos
- 1 kudos
Hi Ruben!I am facing exactly the same error running a similar approach when using runtime 16.2 ML. I didn't have this issue when using runtime 12.2 LTS ML or 13.3 ML. Did you find a solution?Many thanks!
- 1 kudos
- 3412 Views
- 2 replies
- 0 kudos
Can we retrieve experiment results via MLflow API or is this only possible using UI?
Yes, you can use the API https://www.mlflow.org/docs/latest/python_api/index.html
- 3412 Views
- 2 replies
- 0 kudos
- 0 kudos
And how about tracing data? Do you know how to read likespark.read.format("mlflow-experiment").load() ?
- 0 kudos
- 7148 Views
- 6 replies
- 1 kudos
Hosting R apps and models
Hello!Has anyone tried to host an R Shiny app using Databricks apps? It is very useful for Python apps, but it would be nice to know if anyone have any workaround to make it work with R Shiny Apps.We also wonder about Databricks model hosting for R m...
- 7148 Views
- 6 replies
- 1 kudos
- 1 kudos
Hi @parthSundarka!We tried, but had some problems making it work. Do you have a more complete code example? That would be very helpfull!BR, Anton
- 1 kudos
- 2526 Views
- 5 replies
- 0 kudos
Community Edition workspace not found
Suddenly got logout from my account in the Community Edition. When I tried to login again, I received this error message: "We were not able to find a Community Edition workspace with this email. Please login to accounts.cloud.databricks.com to find t...
- 2526 Views
- 5 replies
- 0 kudos
- 0 kudos
Hi @all,I solved the issue by signing up for a new Community Edition account using the same email.The only downside is I lost all my notebooks :(.
- 0 kudos
- 3913 Views
- 4 replies
- 2 kudos
Resolved! Facing issues with passing memory checkpointer in lanngraph agents
Hi,I am trying to create a simple langgraph agent in Databricks, the agent also uses lanngraph memory checkpoint which enables to store the state of the graph. This is working fine when I am trying it in Databricks notebook, but when I tried to log t...
- 3913 Views
- 4 replies
- 2 kudos
- 2 kudos
Hi all. I have the same issue, could you deploy the graph with the MemorySaver?
- 2 kudos
- 8380 Views
- 2 replies
- 2 kudos
Resolved! Understanding compute requirements for Deploying Deepseek-R1-Distilled-Llama Models on databricks
Hi I have read the blog Deploying Deepseek-R1-Distilled-Llama Models on Databricks at https://www.databricks.com/blog/deepseek-r1-databricksI am new to using custom models that are not available as part of foundation models.According to the blog, I n...

- 8380 Views
- 2 replies
- 2 kudos
- 2 kudos
Thanks @Isi, For in-detail explanation. Things are clear now.
- 2 kudos
- 2467 Views
- 2 replies
- 0 kudos
Foundation Model APIs HIPAA compliance
I saw that Foundation Model API is not HIPAA compliant. Is there a timeline in which we could expect it to be HIPAA compliant? I work for a healthcare company with a BAA with Databricks.
- 2467 Views
- 2 replies
- 0 kudos
- 0 kudos
It is now HIPAA compliant: Provisioned throughput endpoints are available with compliance certifications like HIPAA, Model Serving is HIPAA compliant in all regions
- 0 kudos
- 3237 Views
- 2 replies
- 1 kudos
Resolved! Feature store and medallion data location
Hello Folks,If we have 3 environments (dev/preprod/prod) and would like to have medallion data shared among them - I guess delta share is a good way to go. Now if we want to use "Feature Store (FS)" then I am a bit confused and seeking some clarity. ...
- 3237 Views
- 2 replies
- 1 kudos
- 224113 Views
- 70 replies
- 16 kudos
Community Edition Login Issues Below is a list of troubleshooting steps for failing to login with email/password at community.cloud.databricks.com: ...
Community Edition Login Issues Below is a list of troubleshooting steps for failing to login with email/password at community.cloud.databricks.com: Troubleshooting Tips If this is your first time logging in, ensure that you did indeed sign u...



- 224113 Views
- 70 replies
- 16 kudos
- 16 kudos
same problem I have, would you please help to solution ?
- 16 kudos
- 4022 Views
- 4 replies
- 2 kudos
Accessing Unity Catalog's MLFlow model registry from outside Databricks
Hello EveryoneWe are integrating Unity Catalog in our Organisation's Databricks. In our case we are planning to move our inference from Databricks to Kubernetes. In order to make the inference code use the latest registered model we need to query the...
- 4022 Views
- 4 replies
- 2 kudos
- 2 kudos
You can use the MLflow client (in various language specific SDKs) to download model artifacts. For example, see here: https://docs.databricks.com/en/mlflow/models.html#download-model-artifactsWe leverage this pattern to serve models in our K8s stack ...
- 2 kudos
- 10324 Views
- 6 replies
- 3 kudos
Salesforce connection with Databricks
How can we connect with salesforce from databricks without using any third party jar files?
- 10324 Views
- 6 replies
- 3 kudos
- 3 kudos
You can connect to Salesforce from Databricks without using third-party JAR files by leveraging Python and the Salesforce REST API using the simple-salesforce library. Since simple-salesforce is a Python package, you can install it within your Databr...
- 3 kudos
-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
44 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
Devops
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
61 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
3 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
27 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »
| User | Count |
|---|---|
| 90 | |
| 40 | |
| 38 | |
| 28 | |
| 25 |