I'm looking for a good product to use across two clouds at once for Data Engineering, Data modeling and governance. I currently have a GCP platform, but most of my data and future data goes through Azure, and currently is then transfered to GCS/BQ.Cu...
@Karl Andrén :Databricks is a great option for data engineering, data modeling, and governance across multiple clouds. It supports integrations with multiple cloud providers, including Azure, AWS, and GCP, and provides a unified interface to access ...
Have you heard about databricks latest open-source language model called Dolly? It’s a ChatGPT like model that uses the tatsu-lab/alpaca dataset with examples of questions and answers. To train Dolly, you can combine this dataset (simple solution on ...
Thanks for posting this! I am so excited about the possibilities that this can do for us. It's an exciting development in the natural language processing field, and it has the potential to be a valuable tool for businesses looking to implement chatb...
Hello Databricks community!We are facing a strong need of serving some of public and our private models on GPU clusters and we have several requirements:1) We'd like to be able to start/stop the endpoints (best with scheduling) to avoid excess consum...
Hi @Alisher Akh Does @Debayan Mukherjee's answer help? If yes, would you be happy to mark the answer as best so that other members can find the solution more quickly? If not, please tell us so we can help you further. Cheers!
Hi!We have this dbt model that generates a table with user activity in the previous days, but we get this vague error message in the Databricks SQL Warehouse.Job aborted due to stage failure: Task 3 in stage 4267.0 failed 4 times, most recent failure...
@Mattias P - For the executor lost failure, is it trying to bring in large data volume? can you please reduce the date range and try? or run the workload on a bigger DBSQL warehouse than the current one.
Share information between tasks in a Databricks jobYou can use task values to pass arbitrary parameters between tasks in a Databricks job. You pass task values using the taskValues subutility in Databricks Utilities. The taskValues subutility provide...
I'm trying to set the global init script via my Terraform deployment. I did a thorough google search and can't seem to find guidance here.I'm using a very generic call to set these scripts in my TF Deployment.terraform { required_providers { data...
Ok in case this helps anyone else, I've managed to resolve.I confirmed in this documentation the databricks CLI is required locally, wherever this is being executed. https://learn.microsoft.com/en-us/azure/databricks/dev-tools/terraform/cluster-note...
I am running a hugging face model on a GPU cluster (g4dn.xlarge, 16GB Memory, 4 cores). I run the same model in four different notebooks with different data sources. I created a workflow to run one model after the other. These notebooks run fine indi...
You might accumulate gradients when running your Huggingface model, which typically leads to out-of-memory errors after some iterations. If you use it for inference only, dowith torch.no_grad():
# The code where you apply the model
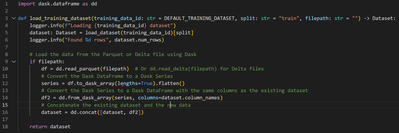
I'd like to continue / finetune training of an existing keras/tensorflow model. We use MLFlow to store the model. How can I load the wieght from an existing model to the model and continue "fit" preferable with a different learning rate.Just loading ...
Hi @Tilo Wünsche Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thank...
Hello,I'm using, in my IDE, Databricks Connect version 9.1LTS ML to connect to a databricks cluster with spark version 3.1 and download a spark model that's been trained and saved using mlflow.So it seems like it's able to find a copy the model, but ...
Hi @Kaniz Fatma and @Shanmugavel Chandrakasu,It works after putting hadoop.dll into C:\Windows\System32 folder.I have hadoop version 3.3.1.I already had winutils.exe in the Hadoop bin folder.RegardsNath
When I save files on "dbfs:/FileStore/shared_uploads/brunofvn6@gmail.com/", it doesn't appear anywhere in my workspace. I've tried to copy the path of the workspace with the right mouse button, pasted on ("my pandas dataframe").to_csv('path'), but wh...
I think I discover how to do this. Is in the label called data in the left menu of the databricks environment, in the top left of the menu there are two labels "Database Tables" and "DBFS" in which "Database Table" is the default label. So it is just...
Had you run vacuum on the table? Vacuum can clean up data files marked for removal and are older than retention period.Optimize compacts files and marks the small files for removal, but does not physically remove the data files
Free Databricks Training on AWS, Azure, or Google CloudGood news! You can now access free, in-depth Databricks training on AWS, Azure or Google Cloud. Our on-demand training series walks through how to:Streamline data ingest and management to build ...
I'm using databricks. Trying to log a model to MLflow using the Feature Store log_model function. but I have this error: TypeError: join() argument must be str, bytes, or os.PathLike object, not 'dict' I'am using the Databricks runtime ml (10.4 LTS M...