- 3422 Views
- 1 replies
- 0 kudos
Resolved! 0: 'error: TypeError("\'NoneType\' object is not callable") in api_request_parallel_processor.py
I´m facing this exception after use mlflow.langchain.log_model and test the logged model using the following commandprint(loaded_model.predict([{"query": "how does the performance of llama 2 compare to other local LLMs?"}]))tasks failed. Errors: {0: ...
- 3422 Views
- 1 replies
- 0 kudos
- 0 kudos
I verified all steps @Retired_mod and the objects and structure were looking good. As far as I understood on tests. Langchain Rag features such as RetrievalQA.from_chain_type does not work well with llm = HuggingFacePipeline instantiation steps. The...
- 0 kudos
- 1950 Views
- 2 replies
- 0 kudos
Input training dataset field empty in Configure AutoML experiment
Trying to start an ML experiment on data in an extant metastore within a catalogue (SQL querys run fine on the database). I can start an ML cluster, then attempt to start an AutoML expirement but I get stuck selecting training data - there are no da...
- 1950 Views
- 2 replies
- 0 kudos
- 0 kudos
you can read SQL data to DataFrame and run AutoML in the notebookTrain ML models with Databricks AutoML Python API | Databricks on AWS
- 0 kudos
- 2619 Views
- 2 replies
- 0 kudos
Upgrading cuDNN on Databricks notebook
I'm trying to upgrade Tensorflow version from 2.8 to 2.13 on Databricks notebook that is attached to a cluster with Databricks Runtime 10.4. How can I upgrade cuDNN from 8.0 to at least 8.6 to be compatible with the Tensorflow new version?
- 2619 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @Retired_mod , Thanks for your response. When I run '!conda list cudnn' on databricks notebook, I get the following error: '/bin/bash: conda: command not found'
- 0 kudos
- 2661 Views
- 0 replies
- 0 kudos
OutOfMemoryError: CUDA out of memory on LLM Finetuning
I am trying to finetune llama2_lora model using the xTuring library, while facing this error. (batch size is 1). I am working on a cluster having 1 Worker (28 GB Memory, 4 Cores) and 1 Driver (110 GB Memory, 16 Cores). I am facing this error: OutOfMe...
- 2661 Views
- 0 replies
- 0 kudos
- 2192 Views
- 0 replies
- 0 kudos
Error in Tensorflow training job
I upgraded Tensorflow on Databricks notebook using %pip command. Now when running the training job, I get this error: "DNN library initialization failed."
- 2192 Views
- 0 replies
- 0 kudos
- 2147 Views
- 1 replies
- 0 kudos
Using AutoML to predict completion dates of a project management dataset
Hello! I am fairly new to Databricks. I'm trying to do a proof of concept with AutoML in Databricks at my organization, and the dataset I am using is a project management dataset. Here's a sample: project_idmarketgeneral_contractorproject_typepermit_...
- 2147 Views
- 1 replies
- 0 kudos
- 8718 Views
- 8 replies
- 2 kudos
Resolved! Scalable ML course error on Lab Setup (Community Edition)
Hello,I am trying to complete the exercises of the course "Scalable Machine Learning with Apache Spark" using Databricks Community Edition, but when I run the Lab Setup I get the following error:HTTPError: 503 Server Error: Service Unavailable for ur...
- 8718 Views
- 8 replies
- 2 kudos
- 2 kudos
I'm experiencing the same issue while using community edition for this classroom: https://github.com/databricks-academy/large-language-models. What subscription level do I upgrade to?
- 2 kudos
- 5573 Views
- 3 replies
- 0 kudos
Resolved! An error occurred while loading the model. Failed to load the pickled function from a hexadecimal
[8586fsbgpb] An error occurred while loading the model. Failed to load the pickled function from a hexadecimal string. Error: Can't get attribute 'transform_input' on <module '__main__' from '/opt/conda/envs/mlflow-env/bin/gunicorn'>.I´m using the fu...
- 5573 Views
- 3 replies
- 0 kudos
- 0 kudos
However I could not progress in the end I mean because I found the error I reported in other thread as follows[5bb99fzs2f] An error occurred while loading the model. You haven't configured the CLI yet! Please configure by entering `/opt/conda/envs/ml...
- 0 kudos
- 5967 Views
- 7 replies
- 0 kudos
Resolved! Why java is no included in notebooks
Hi All,is there any way to use java in notebook ?
- 5967 Views
- 7 replies
- 0 kudos
- 0 kudos
yes spark-submit in jar will work,it is available in the jobs/workflow section in the databricks
- 0 kudos
- 2136 Views
- 1 replies
- 1 kudos
Resolved! Using AutoML in Azure Databricks with a shared cluster
Do you have to use AutoML in Azure Databricks on a personal compute cluster or can you use a shared cluster?Can you point me to some documentation that supports the statement that you can run AutoML on a shared cluster with Azure Databricks?
- 2136 Views
- 1 replies
- 1 kudos
- 1 kudos
Hi @david_stroud Greetings! AutoML is not supported on Shared clusters. Please check the documentation below https://learn.microsoft.com/en-us/azure/databricks/machine-learning/automl/#--requirements
- 1 kudos
- 12488 Views
- 4 replies
- 1 kudos
Mlflowexception: "Connection broken: ConnectionResetError(104, \\\'Connection reset by peer\\\')"
Hello,I have a workflow running which from time to time crashes with the error:MlflowException: The following failures occurred while downloading one or more artifacts from models:/incubator-forecast-charging-demand-power-and-io-dk2/Production: {'pyt...
- 12488 Views
- 4 replies
- 1 kudos
- 1 kudos
Hi @cl2,Thanks for bringing up your concerns; always happy to help Upon going through the details, it appears there was an HTTP connection error downloading artifacts. This typically shouldn’t happen, but it can occur intermittently as a transient n...
- 1 kudos
- 8309 Views
- 6 replies
- 3 kudos
`collect()`ing Large Datasets in R
Background: I'm working on a pilot project to assess the pros and cons of using DataBricks to train models using R. I am using a dataset that occupies about 5.7GB of memory when loaded into a pandas dataframe. The data are stored in a delta table in ...

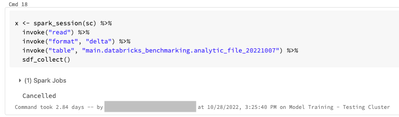
- 8309 Views
- 6 replies
- 3 kudos
- 3 kudos
@acsmaggart Please try using collect_larger() to collect the larger dataset. This should work. Please refer to the following document for more info on the library.https://medium.com/@NotZacDavies/collecting-large-results-with-sparklyr-8256a0370ec6
- 3 kudos
- 3121 Views
- 2 replies
- 5 kudos
How can I view the storage space taken by a registered model using MLFlow?
The information viewed about the registered models on the Models tab is very minimal. Just showing the tags we pass in and version information. How can I get more details about the model such as the size on disk?
- 3121 Views
- 2 replies
- 5 kudos
- 5 kudos
Hi,I have used the MLFlow client, but I am not sure where to find the size of the model image.The response to client.search_registered_models() I am getting is the following:<RegisteredModel: aliases={}, creation_timestamp=17061..., description='', l...
- 5 kudos
- 13229 Views
- 5 replies
- 0 kudos
Resolved! Model serving endpoint requires workspace-access entitlement?
Hi all, is anyone getting status 403 when requesting a model serving endpoint with error message "This API is disabled for users without the workspace-access entitlement"? I am accessing my model serving endpoint with a service principal access token...
- 13229 Views
- 5 replies
- 0 kudos
- 0 kudos
Hi @run480 , We understand that you are facing the following error while you are trying to access the model serving endpoint with a Service Principal Access Token: ++++++++++++++++++++++++++++++++++++++ "This API is disabled for users without the wor...
- 0 kudos
- 1844 Views
- 0 replies
- 0 kudos
Editing posts
Hey,I have a post that I would like to edit. However, when I use the drop down menu there is no possibility to edit or delete the post - can someone help?
- 1844 Views
- 0 replies
- 0 kudos
Join Us as a Local Community Builder!
Passionate about hosting events and connecting people? Help us grow a vibrant local community—sign up today to get started!
Sign Up Now-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
39 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
Devops
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
61 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
2 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
14 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »
| User | Count |
|---|---|
| 90 | |
| 39 | |
| 38 | |
| 25 | |
| 25 |