I'm Avi, a Solutions Architect at Databricks working at the intersection of Data Engineering and Machine Learning.Streaming data processing has moved from niche to mainstream, and deploying machine learning models in such data streams opens up a mult...
I am creating new application and looking for ideas how to handle exceptions in Spark, for example ThreadPoolExecution. Are there any good practice in terms of error handling and dealing with specific exceptions ?
Hi everybody,I created a simple bayesian model using the pymc library in Python. I would like to graphically represent my model using the pymc.model_to_graphviz(model=model) method.However, it seems it does not work within a databrcks notebook, even ...
Hello experts. We are trying to execute an insert command with less columns than the target table:Insert into table_name( col1, col2, col10)Select col1, col2, col10from table_name2However the above fails with:Error in SQL statement: DeltaAnalysisExce...
Hi @ELENI GEORGOUSI Yes. When you are doing an insert, your provided schema should match with the target schema else it would throw an error.But you can still insert the data using another approach. Create a dataframe with your data having less colu...
I've been getting this error pretty regularly while working with mlflow:"It appears that you are attempting to reference SparkContext from a broadcast variable, action, or transformation. SparkContext can only be used on the driver, not in code that ...
I checked the page and it looks like there is no integration with Datarobot and Datarobot doesn't contribute to mlflow. https://mlflow.org/ has all the integrations listed
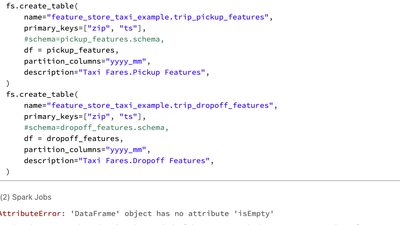
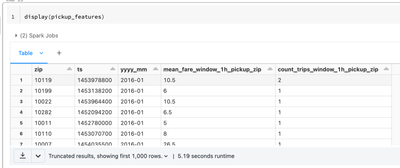
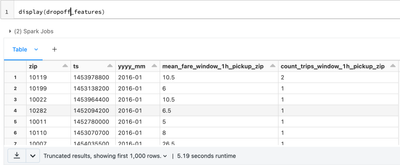
I am following example steps from databricks documentation https://docs.databricks.com/_static/notebooks/machine-learning/feature-store-taxi-example.htmlI am using Feature Store client v0.3.6 and above.However on trying to create feature table with f...
After much digging, observed i was using standard runtime. Once i switched to ML runtime of databricks, issue was resolved. To use Feature Store capability, ensure that you select a Databricks Runtime ML version from the Databricks Runtime Version dr...
I'm attempting to stream into a DLT pipeline with data replicated from Fivetran directly into Delta tables in another database than the one that the DLT pipeline uses. This is not an aggregate, and I don't want to recompute the entire data model eac...
Hi @M A Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question first. Or else bricksters will get back to you soon. Thanks
I have an mlflow experiment with runs in it. When I go to a run's page (with the parameters/metrics/logged artifacts), there is a part that says `git source: my_project_name@some_letters` and I was wondering what that was supposed to point to.When I ...
Last week, we started with using mlflow within databricks. The bayesian models that we are using right now are the pymc3 models (https://docs.pymc.io/en/v3/index.html).We could use the experiment feature of databricks/mlflow to save the models as an ...
Hi @Siebert Looije Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question first. Or else bricksters will get back to you soon. Thanks.
When I log a pyfunc mlflow model, it generates a page that has this helpful code for using the model in production. Make Predictions
Predict on a Spark DataFrame:
import mlflow
from pyspark.sql.functions import struct, col
logged_model = 'runs:/1d......
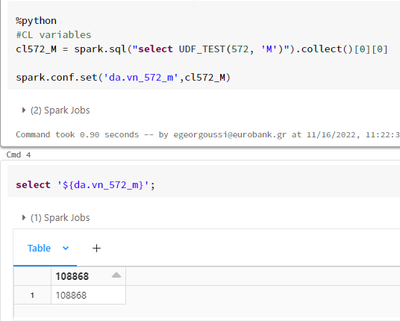
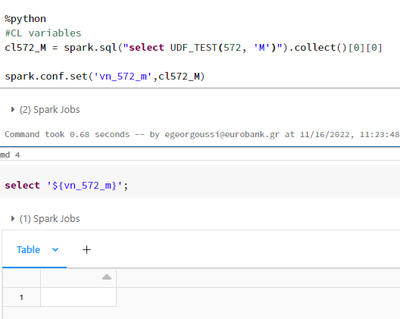
Hello. Could someone please explain at the below example, why having the prefix "da" at the parameter name allows us to select the parameter value but not having it returns to a null value?Correct valueNull value Thank you in advance
Similar to this other question: https://community.databricks.com/s/question/0D58Y00008hahwuSAA/cant-edit-the-cluster-created-by-mlflow-model-servingWe're using Azure Databricks, and have a model that requires a WHL to be downloaded from a private add...
I'm training a ML model (e.g., XGboost) and I have a large combination of 5 hyperparameters, say each parameter has 5 candidates, it will be 5^5 = 3,125 combos.Now I want to do parallelization for the grid search on all the hyperparameter combos for ...
Hi @Chen Mu Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!
For this dataset, I also tried binary file reading as below: xldf_xlsx = (
spark.read.format("binaryFile")
.option("pathGlobFilter", "*.xls*")
.load(filepath_xlsx)
)
excel_content = xldf_xlsx.head(1)[0].content
file_like_obj = io.BytesIO(excel...