- 2802 Views
- 0 replies
- 1 kudos
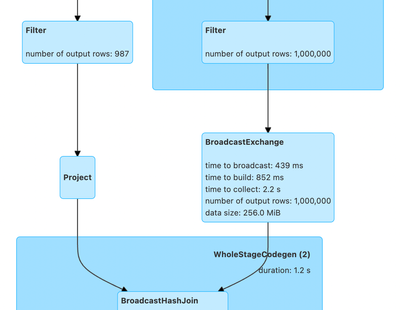
Spark always performing broad casts irrespective of spark.sql.autoBroadcastJoinThreshold during streaming merge operation with DeltaTable.
I am trying to do a streaming merge between delta tables using this guide - https://docs.delta.io/latest/delta-update.html#upsert-from-streaming-queries-using-foreachbatchOur Code Sample (Java): Dataset<Row> sourceDf = sparkSession ...
- 2802 Views
- 0 replies
- 1 kudos