- 972 Views
- 0 replies
- 3 kudos
DE61193D-D4AB-426A-B117-715BBCB67F5F
Excited to hear about Data mesh implementation patterns! Are you using data mesh alread?#summit22
- 972 Views
- 0 replies
- 3 kudos
Excited to hear about Data mesh implementation patterns! Are you using data mesh alread?#summit22
Really excited about Delta Sharing Cleanrooms!
As am I! Between the clean rooms and the platform-agnostic data marketplace, collaborating on a variety of datasets will become much easier than before!
What will happen if a driver node will fail?What will happen if one of the worker node fails?Is it same in Spark and Databricks or Databricks provide additional features to overcome these situations?
If the driver node fails your cluster will fail. If the worker node fails, Databricks will spawn a new worker node to replace the failed node and resumes the workload. Generally it is recommended to assign a on-demand instance for your driver and spo...
I am trying to load parquet files using Autoloader. Below is the code def autoload_to_table (data_source, source_format, table_name, checkpoint_path): query = (spark.readStream .format('cloudFiles') .option('cl...
Hi again @Mayank Srivastava Thank you so much for getting back to us and marking the answer as best.We really appreciate your time.Wish you a great Databricks journey ahead!
When you log in it should be on https://dataaisummit.com/downloads/ but there is nothing yet.
E-khool is an Online Learning Management System software for Industries with low cost and no extra charges. One stop solution for live classes, trainings, videos & materials, unlimited exams, corporate training & professional development, online int...
Hi, Databricks team,I created the share and provided access to the recipient, and the recipient is consuming or accessing the share. My question is who is going to bear the cost and how can we track the computation charges for it?As per the attached ...
Hi @Kaniz Fatma , Thanks for your response on Delta sharing information, Could you please provide details about who is going to bear the cost[either provider/Consumer] and how can we track the computation charges for it?
Hi Team,I am asking a little off topic question here. I have been attending paid session for Data AI summit in last 2-3 years. Is it possible to get videos for sessions which we have not attended due to session conflicts at the same time. I mean to s...
@Juliet Wu Hi Juliet,Thank you so much for sharing the recording. Regards,Rajesh.
I have configured a Databricks job to send email alters to me whenever my job fails. However, I would very much like to alter the text in the Alert Email to something a little more bespoke. Is there any way to alter the text in email or even just t...
Hey there @Peter Mayers Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from yo...
We have created our own artifactory and we use this to install python dependencies or libraries.We would like to know how we can make use of our own artifactory to install dependencies or libraries on Databricks clusters..
For private repos, you can find some good examples herehttps://kb.databricks.com/clusters/install-private-pypi-repo.htmlhttps://towardsdatascience.com/install-custom-python-libraries-from-private-pypi-on-databricks-6a7669f6e6fd
Hello Databricks Community! We are getting so excited about the upcoming event of the year Data & AI Summit! If you still need to sign up, visit our registration page [link]! We have an in-person and virtual option for attending this year. In prepara...
Is there any known issues affecting the creation of clusters? I've been unable to get any clusters to start today so far!Have received this error "Cluster terminated.Reason:Unexpected launch failure"Help!
I am running a massive history of about 250gb ~6mil phone call transcriptions (json read in as raw text) from a raw -> bronze pipeline in Azure Databricks using pyspark. The source is mounted storage and is continuously having files added and we do n...
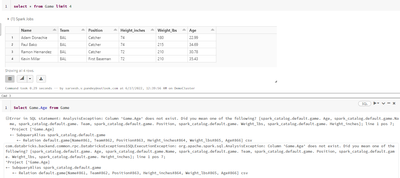
I have loaded the csv file from my local PC to data bricks. Now, when i am trying to query the table over column its throwing error. Note - select * from table_name is working but select column_name from table_name is throwing error.
Thanks for the information, I will try to figure it out for more. Keep sharing such informative post keep suggesting such post.
Hey, So currently I'm using Pyspark and utilizing SparkListener to track metrics of my spark jobs. The problem I can't seem to solve is why in databricks the listener cannot be removed with removeSparkListener as it still is attached to the context.#...
| User | Count |
|---|---|
| 1644 | |
| 793 | |
| 553 | |
| 349 | |
| 287 |