- 4620 Views
- 1 replies
- 2 kudos
How to install JAR libraries from ADLS? I'm having an error
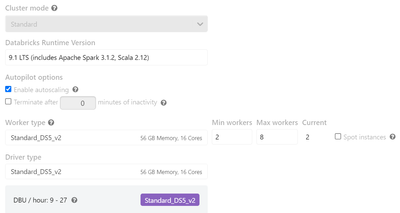
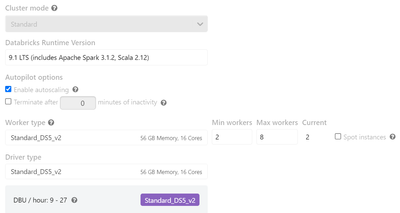
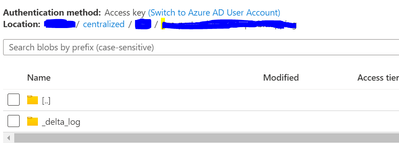
I mounted the ADLS to my Azure Databricks resource and I keep on getting this error when I try to install a JAR from a container:Library installation attempted on the driver node of cluster 0331-121709-buk0nvsq and failed. Please refer to the followi...
- 4620 Views
- 1 replies
- 2 kudos