- 2232 Views
- 0 replies
- 1 kudos
Koalas dropna in DLT
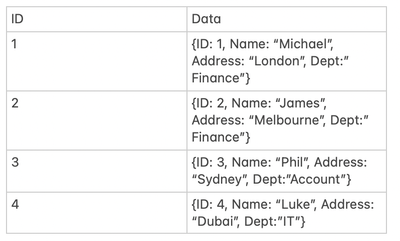
Greetings !I've been trying out DLT for a few days but I'm running into an unexpected issue when trying to use Koalas dropna in my pipeline.My goal is to drop all columns that contain only null/na values before writing it.Current code is this : @dlt...
- 2232 Views
- 0 replies
- 1 kudos