- 21 Views
- 0 replies
- 0 kudos
Certification Coupons
I have completed before june 15th one training. how can i eligible for voucher.
- 21 Views
- 0 replies
- 0 kudos
I have completed before june 15th one training. how can i eligible for voucher.
ContextI'm working on integration patterns between enterprise NAS storage (Amazon FSx for NetApp ONTAP) and Databricks via S3 Access Points. S3 Access Points provide S3 API access to file data without copying — a common pattern for organizations with...
I have a Data Lake Transformation (DLT) pipeline that runs weekly. Normally, it takes 8 minutes to complete, but since last Friday (June 19), it has been running for hours until it encounters an out-of-memory error. This pipeline is responsible for c...
I think this is more like an incremental refresh issue than a generic serverless memory issue.Since the pipeline completes in around 20 minutes with a full refresh, but the normal weekly run runs for hours and then fails with OOM, I would first recom...
SummaryI'm exploring GDPR delete propagation through a medallion architecture (Bronze → Silver → Gold) using Auto CDC with Change Data Feed. Delete events propagate successfully from Landing → Bronze, but fail to propagate from Bronze → Silver → Gold...
Hi @Surya2 , Nice write-up. The symptom you're describing, where updates propagate cleanly but deletes quietly disappear, is a common one, and the good news is that the pattern you're after is fully supported. The break is almost certainly in how you...
I'm prototyping a cluster cost / right-sizing advisor and wanted to get a reality-check from people running Databricks at real scale before I sink more time into it.The main thing I'm chasing is Photon fallback. Photon quietly drops to the JVM on uns...
Hey @Yogasathyandrun , I did some digging and would like to share some thoughts that you hopefully find useful. You've mapped the boundary here more accurately than most people do, so let me give you a quick reality check on your four sticking points...
Hi,It is currently not possible to specify a list of tables to refresh and their refresh policies (full/normal) in a Lakeflow Job.It can be done via the REST API, but it's messy.For example, if you need some tables or views refreshed more regularly, ...
This is a real limitation in the current Lakeflow / DLT job model.Today, a pipeline is treated as the unit of refresh, not individual tables inside it. That means:You can run or fully refresh a pipelineBut you cannot define different refresh policies...
I have one DLT pipeline in Databricks. When I schedule the pipeline, the data is not showing. However, when I run the pipeline manually, the data is displayed properly
A few details would help narrow this down.When the scheduled run executes:Does the pipeline update show Succeeded or Failed?In the pipeline Event Log, do you see rows being processed/written?Is your manual run a normal update or a Full Refresh?Is the...
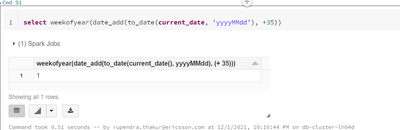
Hi Folks,I've requirement to show the week number as ww format. Please see the below codeselect weekofyear(date_add(to_date(current_date, 'yyyyMMdd'), +35)). also plz refre the screen shot for result.
"I've been exploring different communities lately, and honestly, connecting with people who share your interests makes all the difference. Whether it's diving deep into data engineering discussions or just having random conversations on platforms lik...
Can anyone recommend high-quality study materials or resources (courses, documentation, practice exams, etc.) that helped you prepare for the Professional-level exam?
Recently achieved this certification and it feels great to see all the hard work pay off. Consistent practice, hands-on learning, and quality study resources made a huge difference. For anyone preparing, I found this resource helpful: https://linkly....
Hi Everyone,Today I gave databricks exam for and I got 64 questions and my result was exactly 70.00%(As per databricks the pass percentage is 70 or above). but still the status was showing Failed and I couldn't get certified.Can you anyone help me on...
Congratulations on this achievement! Reaching this milestone feels incredibly rewarding. I had a similar experience, and quality practice resources from https://linkly.link/2l2Hb were very helpful throughout my preparation journey.
Hi,I was doing a POC and hence used open source spark and kafka in docket container and got it working. The sample code is ingesting data from kafka but it is running only in batch mode. Not able to continuously ingest the kafka streamQuestion: Can w...
Yes, we can build a continuous streaming pipeline using open source Spark. The main thing is to use Spark Structured Streaming, not a normal batch read. For Kafka streaming, we need to use spark.readStream, then write using writeStream, and keep the ...
I want to run some SQL commands programmatically against and decided to use Genie Code to help me, it came up with unsupported and non-existent commands.

The command shown in the screenshot appears to be hallucinated.databricks sql-statements execute is not a valid Databricks CLI command. It looks like Genie combined concepts from the SQL Statement Execution API with CLI syntax that doesn't actually e...
Hi,I am using autoloader to load parquet files into my unity catalog with the following settings:.option("cloudFiles.format", "parquet") .option("cloudFiles.inferColumnTypes", "true") .option("cloudFiles.schemaEvolutionMode", "addNewColumnsWithTypeWi...
What you're seeing comes down to where the type mismatch is detected.For Parquet, some mismatches can be handled at the Auto Loader layer and end up in _rescued_data, while others fail earlier inside the Parquet reader itself.In your example, the exi...
I am using SQL Server, Postgres, and MongoDB as data sources, connecting through Spark and JDBC connector. I would like to store the credentials and connection details in Databricks, pass them as job parameters, and need guidance on possible approach...
I'd think about this as a separation of concerns:Secrets are for sensitive values (usernames, passwords, tokens, connection URIs).Job parameters are for runtime values (connection name, database, schema, table, query, collection, source system).In mo...
HiWe are trying to generate fake data to run our tests. For example, we have a pipeline that creates a gold layer fact table form 6 underlying source tables in our silver layer. We want to generate the data in a way that recognises the relationships ...
The core problem you're facing is that Delta Lake doesn't enforce foreign key constraints, so most datagen tools generate each table independently and your joins produce no meaningful overlap.The solution is to generate a shared key pool first - a si...
| User | Count |
|---|---|
| 1644 | |
| 793 | |
| 575 | |
| 349 | |
| 287 |