Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
The course "Apache Spark™ Programming with Databricks" requires data sources such as training/ecommerce/events/events.parquet. Are these available as CSV files? My company's databricks configuration does not allow me to mount to such repositories, bu...
I am using a specific Pydeeque function called ColumnProfilerRunner which is only supported with Spark 3.0.1, so I must use 7.3 LTS. Currently, I am trying to install "great_expectations" library on Python, which requires Ipython version==7.16.3, an...
@Hitesh Goswami : please check if the below helps!To upgrade the Ipython version on a Databricks 7.3LTS cluster, you can follow these steps:Create a new library installation command using the Databricks CLI by running the following command in your l...
I am new to azure databricks and I want to install a library on a cluster and to do that I need to install bazel build tool first.I checked the site bazel but I am still not sure how to do it in databricks?I appriciate if any can help me and write me...
Databricks migrated over from the standard Scala Build Tool (SBT) to using Bazel to build, test and deploy our Scala code. Follow this doc https://www.databricks.com/blog/2019/02/27/speedy-scala-builds-with-bazel-at-databricks.html
Hi Everyone, I would like to a Pandas Dataframe to /dbfs/FileStore/ using to_csv method.Usually it would just write the Dataframe to the path described but It has been giving me "FileNotFoundError: [Errno 2] No such file or directory: '/dbfs/FileStor...
https://docs.databricks.com/security/keys/customer-managed-keys-storage-aws.html#introductionThe Databricks cluster’s EBS volumes (optional) - For Databricks Runtime cluster nodes and other compute resources in the Classic data plane, you can option...
We use Azure Devops and Azure Databricks and have custom Python libraries. I placed my notebooks in the same repo and the structure is like this:mylib/
mylib/__init__.pyt
mylib/code.py
notebooks/
notebooks/job_notebook.py
setup.pyAzure pipelines buil...
There will be no performance impact if you want to keep " Delta log retention to 3000". However, it will increase the storage cost so it's not advisable to use a large number until really needed for the business use cases.The default delta.logRetenti...
You need to test in Python and scala based on the complexity one of it outperforms the other. In few cases Python was faster where as in other Scala. It is all about the efficiency of the code
To create external tables we need to use the location keyword and use the link for the storage location, in reference to that does the user need to have permission for the storage location if not then will we use storage credentials to provide the ac...
Hi Nimai, That's partially right. You can grant permissions directly on the storage credential, but Databricks recommends that you reference it in an external location and grant permissions to that instead. An external location combines a storage cre...
I’m trying to use sql query on azure-databricks with distinct sort and aliasesSELECT DISTINCT album.ArtistId AS my_alias
FROM album ORDER BY album.ArtistIdThe problem is that if I add an alias then I can not use not aliased name in the order by cla...
I have a streaming notebook which fetches messages from confluent Kafka topic and loads them into adls. It is a streaming notebook with the trigger as continuous processing. Before loading the message (which is in Avro format), I'm flattening out the...
Best approach is to not to depend on Kafka’s commit mechanism! We can store processing result and message offset to external data store in the same database transaction. So, if the database transaction fails, both commit and processing will fail and ...
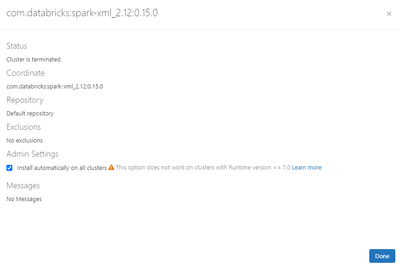
Even after maven library installation using the Auto installation.spark.read.option("rowTag", "tag").xml("dbfs:/mnt/dev/bronze/xml/fileName.xml")not working.
At present DLT does not support installing the maven library from the DLT pipeline. In the future this feature will come for sure so please wait for some time and keep checking data bricks runtime release docs https://docs.databricks.com/release-note...
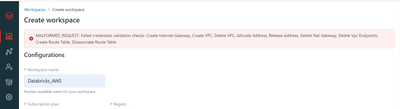
I am trying to configure databricks with AWS, I have configured the cloud resources as described in this https://docs.databricks.com/administration-guide/account-api/iam-role.html#language-Databricks%C2%A0VPC I have selected "Your VPC Default" as the...
@samruddhi ChitnisCan you please check the below troubleshooting guide : Credentials configuration error messages: Malformed request: Failed credential configuration validation checksThe list of permissions checks in the error message indicate the li...
a bit old, but I just faced the same issue, specifying a custom EncryptionMaterialsProvider (as described in the previous post) did the trick for me but I did had to also specify my kms endpoint, just because my region:"fs.s3.cse.kms.endpoint" -> "km...
I am trying to pass parameter from SSRS to User Defined Function in Databricks which in turn will return table that will be shown as output in report.I tried below calling function from SSRS, but it looks like parameter value is not passed. I have di...