Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
I am looking for details on how Delta Sharing is configured on Azure. If your storage account is private, do you need to whitelist the IP for the recipient? Recipient is not using Databricks.
Hello,I'm using a local Docker Spark 3.5 runtime to test my Databricks Connect code. However I've come across a couple of cases where my code would work in one environment, but not the other.Concrete example, I'm reading data from BigQuery via spark....
@dollyb That's because when you've added another dependency on Databricks, it doesn't really know which one it should use. By default it's using built-in com.google.cloud.spark.bigquery.BigQueryRelationProvider.What you can do is provide whole packag...
Hello All, We want to update our postgres tables from our spark structured streaming workflow on Databricks. We are using foreachbatch utility to write to this sink. I want to understand an optimized way to do this at near real time latency avoidi...
Hi, I need to integrate Azure Devops repos with AWS Databricks, but not via personal token.I need it via main service, integrated with Azure Entra ID, using Azure Databricks when I go to create main service, "Entra ID application ID" appears, but in ...
Hi everbody, I am facing a issue with spark structured steaming. here is a sample of my code: df = spark.readStream.load(f"{bronze_table_path}") df.writeStream \ .format("delta") \ .option("checkpointLocation", f"{silver_checkpoint}") \ .option("me...
My first message was not well formatted. i wrote : df = spark.readStream.load(f"{bronze_table_path}")
df.writeStream \
.format("delta") \
.option("checkpointLocation", f"{silver_checkpoint}") \
.option("mergeSchema", "true") \
.trigger(availabl...
I created a new workspace on Azure Databricks, and I can't get past this first step in the tutorial: DROP TABLE IF EXISTS diamonds;
CREATE TABLE diamonds USING CSV OPTIONS (path "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", hea...
Hi Team,Currently I am trying to find size of all tables in my Azure databricks, as i am trying to get idea of current data loading trends, so i can plan for data forecast ( i.e. Last 2 months, approx 100 GB data came-in, so in next 2-3 months there ...
Hi @Retired_mod,1- Regarding this issue i had found below link:https://kb.databricks.com/sql/find-size-of-table#:~:text=You%20can%20determine%20the%20size,stats%20to%20return%20the%20sizeNow to try above link, I need to decide: Delta-Table Vs Non-De...
Hello,The webhook notifications in databricks jobs defined in the asset bundles are not taken into account and therefore not created. For instance, this is not working:resources: jobs: job1: name: my_job webhook_notifications: on...
Hello @Retired_mod ,Thank you for your help.However we did check the job configuration multiple time. If we substitue 'webhook_notifications' with 'email_notifications' it works, so the syntax is correct. Here is a sample of our configuration:For the...
Dear Community,I'm using the COPY INTO command to automate the staging of files that I get in an S3 bucket into specific delta tables (with some transformation on the fly).The command works smoothly, and files are indeed inserted only once (writing i...
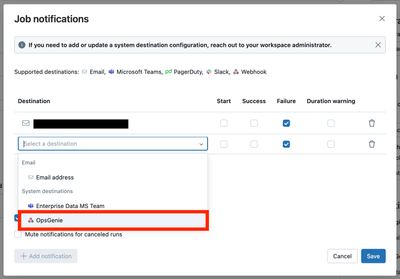
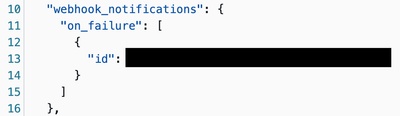
I'm trying to set up a Workflow Job Webhook notification to send an alert to OpsGenie REST API on job failure. We've set up Teams & Email successfully.We've created the Webhook and when I configure "On Failure" I can see it in the JSON/YAML view. How...
What is this short-lived token shared by unity-catalog in step 4 and 5 here? And how does the cloud storage authenticate the token generated by unity catalog?
I'm reading data from the default endpoint of an IoT hub in azure using the kafka connector in Databricks. Most data items are straight forward, but the device id and the timestamp I haven't been able to properly decodeFor example, the key-value map...
Hello all, I am relatively new in data engineering and working on a project requiring me to programmatically delete data from delta live tables. However, I found that simply stopping the streaming job and deleting rows from the delta tables caused th...
I created a Workflow with notebooks and some job runs, but I would to use only one job cluster to run every job runs, without creating a new job cluster for each job run. Because I didn't want to increase the execution time with each new job cluster ...
Hi,If I understand correctly, you are hoping to reduce overall job execution time by reducing the Cloud Service Provider instance provisioning time. Is that correct?If so, you may want to consider:
Using a Pool of instances: https://docs.databricks.c...
I'm trying to perform a merge inside a streaming foreachbatch using the command: microBatchDF._jdf.sparkSession().sql(self.merge_query)Streaming runs fine if I use a Personal cluster while if I use a Shared cluster streaming fails with the following ...
Can you share what runtime your cluster is using?
This error doesn't surprise me, Unity Catalog Shared clusters have many security limitations, but the list is reducing over time. https://docs.databricks.com/en/compute/access-mode-limitations.html#s...