Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
I am able to ues expectation feature in delta live table using by creating the expectations as below checks = {}checks["validate circuitId col for null values"] = "(circuitId IS not NULL)"checks["validate name col for null values"] = "(name IS not ...
HI All,We are ingesting 1000 files in json format and different sizes per minute. DLT is in continuous mode. Unity Catalog is enabled workspace. We are using the default setting of Autoloader (Directory Listing) and Silver has CDC as well.We aim to ...
Hi Team,We have a job it completes in 3 minutes in one Databricks cluster, if we run the same job in another databricks cluster it is taking 3 hours to complete.I am quite new to Databricks and need your guidance on how to find out where databricks s...
We are using unity catalog.Is there a way to set up relations in unity catalog tables like key column relations, 1 to many, many to 1.Can we also generate ER diagrams if we are able to set up these relations.
HiI am using DLT with Autoloader.DLT pipeline is running in Continuous mode.Autoloader is in Directory Listing mode (Default)Question.I want to move files that has been processed by the DLT to another folder (archived) and planning to have another no...
Hi, When using the MERGE statement, if merge key is not unique on both source and target, it will throw error. If merge key is unique in source but not unique in target, WHEN MATCHED THEN DELETE/UPDATE should work or not? For example merge key is id....
Cool, this is what I tested out. Great to get confirmed. Thanks. BTW, https://medium.com/@ritik20023/delta-lake-upserting-without-primary-key-f4a931576b0 has a workaround which can fix the merge with duplicate merge key on both source and target.
I have a SQL query that generates a table. I created a visualization from that table with the UI. I then have a widget that updates a value used in the query and re-runs the SQL, but then the visualization shows nothing, that there is "1 row," but if...
I want to install my own Python wheel package on a cluster but can't get it working. I tried two ways: I followed these steps: https://docs.databricks.com/en/workflows/jobs/how-to/use-python-wheels-in-workflows.html#:~:text=March%2025%2C%202024,code%...
@397973 - Once you uploaded the .whl file, did you had a chance to list the file manually in the notebook?
Also, did you had a chance to move the files to /Volumes .whl file?
Hi,I have a delta live table workflow with storage enabled for cloud storage to a blob store.Syntax of bronze table in notebook===@dlt.table(spark_conf = {"spark.databricks.delta.schema.autoMerge.enabled": "true"},table_properties = {"quality": "bron...
Hi Kaniz,Thanks for replying back.I am using python for delta live table creation, so how can I set these configurations?When creating the table, add the IF NOT EXISTS clause to tolerate pre-existing objects.consider using the OR REFRESH clause Answe...
I am facing an issue when using databricks, when I set a specific type in my schema and read a json, its values are fine, but after saving my df and loading again, the value is gone.I have this sample code that shows this issue: from pyspark.sql.typ...
I have a requirement to read and parse JSON files using autoloader where incoming JSON file has multiple sub entities. Each sub entity needs to go into its own delta table. Alternatively we can write each entity data to individual files. We can use D...
I think using DLT's medallion architecture should be helpful in this scenario. You can write all the incoming data to one bronze table and one silver table. And you can have multiple gold tables based on the value of the sub-entities.
Hi,I'm trying to do the vacuum on a Delta table within a unity catalog. The default retention is 7 days. Though I vacuum the table, I'm able to see the history beyond 7 days. Tried restarting the cluster but still not working. What would be the fix ?...
No, that's wrong. VACUUM removes all files from the table directory that are not managed by Delta, as well as data files that are no longer in the latest state of the transaction log for the table and are older than a retention threshold.VACUUM - Azu...
How can I fix the IP address of my Azure Cluster so that I can whitelist the IP address to run my job daily on my python notebook? Or can I find out the IP address to perform whitelisting? Thanks
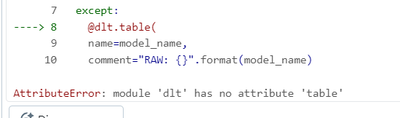
Hi Everyone,I am new to DLT and am trying to run below code to create table dynamically. But I get error "AttributeError: module 'dlt' has no attribute 'table'". code snippet:def generate_tables(model_name try: spark.sql("select * from dlt.{0}"....
Thank You, @DE_K. I see your point. I believe you are using the @dlt.table instead of @dlt.create_table to begin with, since want the table to be created and not define and existing one. (https://community.databricks.com/t5/data-engineering/differenc...