Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Hello everyone !I currently have a DLT pipeline that loads into several Delta LIVE tables (both streaming and materialized view).The end table of my DLT pipeline is a materialized view called "silver.my_view".In a later step I need to join/union/merg...
I have to divide a dataframe into multiple smaller dataframes based on values in columns like - gender and state , the end goal is to pick up random samples from each dataframeI am trying to implement a sample as explained below, I am quite new to th...
@raela I also have similar usecase. I am writing data to different databricks tables based on colum value.But I am getting insufficient disk space error and driver is getting killed. I am suspecting df.select(colName).distinct().collect()step is taki...
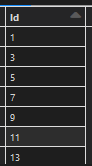
Hi,I'm doing merge to my Delta Table which has IDENTITY column:Id BIGINT GENERATED ALWAYS AS IDENTITYInserted data has in the id column every other number, like this:Is this expected behavior? Is there any workaround to make number increasing by 1?
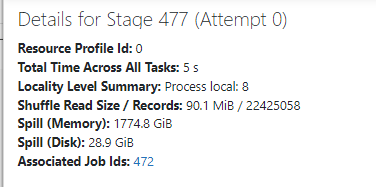
HI Everyone,Im trying to merge two delta tables who have data more than 200 million in each of them. These tables are properly optimized. But upon running the job, the job is taking a long time to execute and the memory spills are huger (1TB-3TB) rec...
I have source data with multiple rows and columns, 1 of column is city. I want to get unique city into other table by stream data from source table. So I trying to use merge into and foreachBatch with my merge function. My merge condition is : On so...
Hello:In my Hive Metastore, I have 35 tables in database that I want to export in excel. I need help on query that can loop one table at a time export one table to excel.Any help is appreciated.Thanking in advance for your kind help.
Unable to start the Cluster in AWS-hosted Databricks because of the below reason{
"reason": {
"code": "BOOTSTRAP_TIMEOUT",
"parameters": {
"databricks_error_message": "[id: InstanceId(i-0634ee9c2d420edc8), status: INSTANCE_INITIALIZIN...
Hi, Sahha:
Thanks for contacting Databricks Support.
This is the common type of error, which indicates that the bootstrap failed due to a misconfigured data plane network. Databricks requested EC2 instances for a new cluster, but encountered a long ...
Hi Experts,Recently our team noticed that when we are using Aparch Sedona to create the parquet file with Geoparquet format, the geo metedata was not created inside the parquet file. But if we turn off the Photon setting, everything was working as ex...
Hi @Madhur,
The difference between Auto Optimize set on Spark Session and the one set on Delta Table lies in their scope and precedence.
Auto Optimize on Spark Session will apply to all Delta tables in the current session. It is a global configuratio...
OperationalError: 250003: Failed to get the response. Hanging? method: get, url: https://cdodataplatform.east-us-2.privatelink.snowflakecomputing.com:443/queries/01ae7ab6-0c04-e4bd-011c-e60552f6cf63/result?request_guid=315c25b7-f17d-4123-a2e5-6d82605...
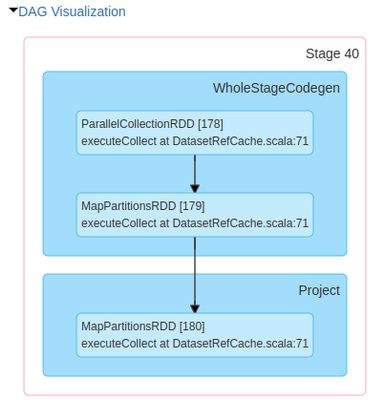
I find it quite hard to understand Spark UI for my pyspark pipelines. For example, when one writes `spark.read.table("sometable").show()` it shows:I learned that `DataFrame` API actually may spawn jobs before running the actual job. In the example ab...
Hello everyone!I've been working with the Databricks platform for a few months now and I have a suggestion/proposal regarding the UI interface of Workflows.First, let me explain what I find not so ideal.Let's say we have a job with three Notebook Tas...
Hi Everyone,I am running job task using Asset Bundle.Bundle has been validated and deployed according to: https://learn.microsoft.com/en-us/azure/databricks/dev-tools/bundles/work-tasksPart of the databricks.yml bundle:
name: etldatabricks
resourc...
I am trying to read 30 xml files and create a dataframe of the data of each node but i takes alot of time approximately 8 mins to run those files what i can i do to optimize the databricks notebook and i append the data in a databricks delta table