Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
I have a Databricks notebook and I have several headers, SQL commands and their output. I am currently copying the output and SQL commands manually to excel for a report. How can I reduce the manual work of copy pasting from Notebook to excel and au...
Hello,I'm trying to use Databricks on Azure with a Spark structured streaming job and an having very mysterious issue.I boiled the job down it it's basics for testing, reading from a Kafka topic and writing to console in a forEachBatch.On local, ever...
@Hubert Dudek Thanks for the information. It is working.I have one more question:Is notebook saves changes automatically ?? If yes, I can see 'save now' option on top right corner(where user details shows/Version details shows) what is use of that o...
Hi @Sufyan Shafique We are really sorry for the delays.Just a friendly- follow-up, have you got your certification and badge? If yes, please mark the answer as best.Thanks and Regards
Hi Everyone,I was wondering if anyone here has any experience or tips reading data from AWS DocumentDB. I am working on this using the MongoDB connector. For DocumentDB we also need to work with the required creds issued as a .pem file by AWS. Th...
Hi @Kaniz Fatma ,Thank you so much for your response. Your suggestions were helpful. As per the AWS documentation, DocumentDB is MongoDB compatible. "With Amazon DocumentDB, you can run the same application code and use the same drivers and tools th...
I have 2 very similarly configured workspaces, one in us-west-2 and one in us-east-2.Both got configured by default with a "Starter Warehouse".The one in us-west-2 I can reach via the internet using python databricks-sql-connector, but the one in us-...
Hi @Marcus Simonsen Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Th...
In databricks I am trying to read data from a protected kafka topic using pyspark.I am getting an error "unable to find LoginModule class: org.apache.kafka.common.security.plain.PlainLoginModule".
Hi team, I started getting this message lately when trying add some new config or change my workspace with terraform :Error: cannot create global init script: authentication is not configured for provider. Please check https://registry.terraform.io/p...
Hi @Avi Edri looks like you are using a provider that is authenticated to the Accounts console (https://accounts.cloud.databricks.com) to create a global init script within the workspace. Can you try authentication with host and PAT token? Follow th...
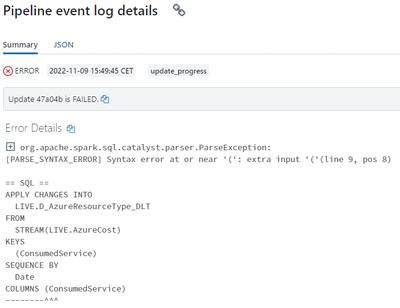
I have a notebook with the code below, where I try to do an upsert into a dimension table and only include one column from the source table. I get an error even though I think the syntax matches what I see in the docs. How can I write this in the cor...
I am trying to use selenium webdriver to do a scraping project in Databricks. The notebook used to run properly but now has an issue with the Get:1 http://archive.ubuntu.com/ubuntu focal/main amd64 fonts-liberation all 1:1.07.4-11 [822 kB]command .In...
Hi, @Dagart Allison . I've created a new version of the selenium with the databricks manual. Please look here https://community.databricks.com/s/feed/0D58Y00009SWgVuSAL
I have a notebook that uses a Selenium Web Driver for Chrome and it works the first time I run the notebook. If I run the notebook again, it will not work and gives the error message: WebDriverException: Message: unknown error: unable to discover op...
Hi, @Dagart Allison . I've created a new version of the selenium with the databricks manual. Please look here https://community.databricks.com/s/feed/0D58Y00009SWgVuSAL
We are migrating a job from onprem to databricks. We are trying to optimize the jobs but couldn't use bucketing because by default databricks stores all tables as delta table and it shows error that bucketing is not supported for delta. Is there anyw...
Hi @Arun Balaji ,bucketing is not supported for the delta tables as you have noticed.For the optimization and best practices with delta tables check this:https://docs.databricks.com/optimizations/index.htmlhttps://docs.databricks.com/delta/best-prac...
Hi team, Users are unable run select on data located on S3 buckets, S3 permission are ok.The only way they manage do it by granted the databricks workspace admin permission.Attached the error.Thanks!
@Avi Edri adding some more info to @Pat Sienkiewicz suggestion, @Avi Edri are you using cluster with instance profile, if you are using instance profile configured, please validate read permissions are there on that bucket and instance profile ass...
Hello all,I'm currently trying to move the tables contained in one azure workspace to another, because of a change in the way we use our resources groups. I have not been able to move more than metadata with the databrickslabs/migrate repo. I was won...
Hi @Quentin Maire ,We need a bit more details.where is your data stored ?are you using external or managed tables?the migrate tool allows you to export DDL statements not the data itself.I can think about few scenarios on Top of my head.if you had p...
We are having multiple joins involving a large table (about 500gb in size). The output of the joins is stored into multiple small files each of size 800kb-1.5mb. Because of this the job is split into multiple tasks and taking a long time to complete....