Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Hi, when I add a new user from admin console, the name of the user is empty. It does not happen all the time. For some users, the username and name both are available. But for some new users, the value in the name column in the users list is empty. W...
Currently we're getting reports of compute resources disappearing from one of our lesser used databricks platforms. I just turned on logging to see if we can find something but I'm wondering if a compute gets removed if it hasn't been used after so l...
Pest Control Software to Grow Your Business Choosing the best pest control software for your business can have a powerful impact on your productivity. Fieldwork can help your workforce repel downtime, attract clients, get organized and get everything...
When I am trying to read data from elasticsearch by spark sql, it throw an error like RuntimeException: Error while encoding: java.lang.RuntimeException: scala.collection.convert.Wrappers$JListWrapper is not a valid external type for schema of string...
Hi there @KARTHICK N Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.T...
Hello everyone,I need to connect Databricks Pyspark to get information from Power BI XLMA EndPoint - the end point work as an SSAS host.So, I'm trying to find what I need to do to connect to SSAS tabular. Can anyone help?Many thanks.Rodrigo Souza
Hey there @Rodrigo Camara de Souza Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to h...
To make a long story short, through SCIM we accidentally provisioned 3,000+ users into our Databricks workspace who should not be there. We fixed the SCIM issue but now the workspaces tab is flooded with inactive user workspaces. Is there any way to ...
Hello @David Kruetzkamp Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from yo...
I have monthly files which comes in S3 bucket. I want to implement SCD type2 in snowflake.I am ok to read the new files, clean it.My question is about comparing what I have read from the files, with what is stored in the snowflake table already(milli...
The Next Databricks Office HoursOur next Office Hours session is scheduled for January 25, 2022 - 8:00 am PDTDo you have questions about how to set up or use Databricks? Do you want to get best practices for deploying your use case or tips on data ar...
Thank you for the opportunity to communicate. I work at https://www.eliteimagingsystems.com/ and know how important it is for our customers to be able to communicate with us 24/7.
What is the maximum of concurrent streaming jobs for a cluster? How can I have the right amount of concurrent streaming jobs for different cluster configuration?Should I use multiple cluster for different jobs or combine it into a big cluster to hand...
I am a newbie to data bricks and trying to write results into the excel/ CSV file using the below command but getting DataFrame' object has no attribute 'to_csv' errors while executing.I am using a notebook to execute my SQL queries and now want to s...
Hi there @Dipak Bachhav Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from yo...
Hi there,In my current project, Current status: Az databricks streaming jobs migrate Json file from kafka to raw layer(parquet file), then parsing logic is applied and 8 tables are created in raw standardized layer.Requirement: Business team wants to...
You could indeed use ADF to copy the data from cloud to on-prem.However, depending on the size of the data, this can take a while.I use the same pattern, but for aggregated processed data, which is not an issue at all.You could also look at Azure Syn...
This issue is oddly only on an Azure Windows 10 VM. I Dont have this on my workstation or my personal computer so it seems to be host config related. The VM where the issue is i have a simple python script that connects to the Azure Databricks SQL en...
Hello @Wayne Theron Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Th...
Hi all,I am new to the databricks. I am trying to get the data from S3. The video tutoirals from the streaming platforms are accessing via access ID and secret access key. However, databricks is throwing a different options. I dont know what to fill...
Hi @Karthikeyan Palanisamy Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from...
I am trying to connect my Spark cluster to a Postgresql RDS instance. The Python notebook code that was used is seen below:df = ( spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql://<connection-string>:5432/database”)\
.option("dbt...
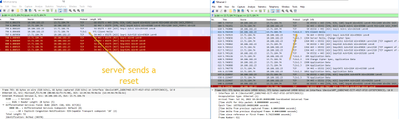
"Caused by: java.net.SocketTimeoutException: connect timed out" indicate the network connection between Databricks cluster and the postgress database on 5432 port was not established and eventually timed out.As a first step, please ensure the connect...
I have an Azure Logic app which triggers whenever a HTTP Post request is received. I want to send this request from my notebook present in Azure Databricks workspace using scala and spark. Is it possible? If yes, then please guide on how to do it. T...
Hey there @Ayushri Jain Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from yo...
I have a large table which contains a date_time column.The table contains 2 generated columns year, and month which are extracted from the date_time values and are used for partitioning.I have the following question.If I run the querySELECT *FROM tab...
Hi @Andrej Znidarsic Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.T...