Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Hi all,I've recently checked my bucket size on AWS and saw that it's size doesn't make much sense. I decided to vacuum each delta table with 2 weeks of retention. That shrunk the data from 30TB to around 5TB, though I was wondering, shouldn't default...
Hello! I want to ask a question please!Referring to Spot VMs with the "Cost Optimized" setting:In the case of Endpoint X-Small, which are 2 workers, if I send 10 simultaneous queries and a worker is evicted, can I have an error in any of these querie...
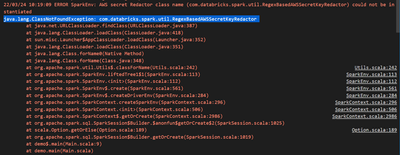
Hello Team,I am quite new to Databricks and I am learning PySpark and Databricks. I am trying to mount a DL Gen2 in Databricks, as part of that I had created app registration, added DL into app registration permissions, created a secret and also adde...
Delta time travel - recover unconditionally deleteRecovery is a great feature of the delta. Let's check with a real example of how recovery option work.Please watch my new youtube video about that topic.https://www.youtube.com/watch?v=TrUT6pvFKic
My job started failing with the below error when inserting rows into a delta table. ailing with the below error when inserting rows (timestamp) to a delta table, it was working well before.java.lang.ArithmeticException: Casting XXXXXXXXXXX to int cau...
This is because the Integer type represents 4-byte signed integer numbers. The range of numbers is from -2147483648 to 2147483647.Kindly use double as the data type to insert the "2147483648" value in the delta table.In the below example, The second ...
I have configured a Delta Lake Sink connector which reads from an AVRO topic and writes to the Delta lake . I have followed the docs and my config looks like below . { "name": "dev_test_delta_connector", "config": { "topics": "dl_test_avro", "inp...
@Hubert Dudek , Should I be configuring anything with respect to schema in the connector config ? Because I did successfully stage some data from another topic of a different format(JSON_SR) into delta lake table , but its with AVRO topic that I ge...
I am trying to use Databricks Delta Lake Sink Connector(confluent cloud ) and write to S3 . the connector starts up with the following error . Any help on this could be appreciated org.apache.kafka.connect.errors.ConnectException: java.sql.SQLExcepti...
All SQL endpoints have delta cache enabled out of the box (in fact 2X-Small etc. are E8/16 etc. instances which are delta cache enabled). Delta cache is managed dynamically. So it stays till there is free RAM for that.
I have a Java program like this to test out the Databricks JDBC connection with the Databricks JDBC driver. Connection connection = null;
try {
Class.forName(driver);
connection = DriverManager.getConnection(url...
Hi @Jose Gonzalez ,This similar issue in snowflake in JDBC is a good reference, I was able to get this to work in Java OpenJDK 17 by having this JVM option specified:--add-opens=java.base/java.nio=ALL-UNNAMEDAlthough I came across another issue with...
I have a delta table with about 300 billion rows. Now I am performing some operations on a column using UDF and creating another columnMy code is something like thisdef my_udf(data):
return pass
udf_func = udf(my_udf, StringType())
data...
That udf code will run on driver so better not use it for such a big dataset. What you need is vectorized pandas udf https://docs.databricks.com/spark/latest/spark-sql/udf-python-pandas.html
CommunityI'm running a sparklyr "group_by" function and the function returns the following info:# group by event_typeacled_grp_tbl <- acled_tbl %>% group_by("event_type") %>% summary(count = n()) Length Cl...
I should have deleted the post. While your are correct "event_type" should be without quotes the problem was the Summary function. I was using the wrong function it should have been "summarize."
We all have been in the situation at some time where we wonder how to stop liking someone. There could be any reason behind this situation and might be any person: your crush, love, friend, relatives, colleague, or any celebrity. Liking is the strong...
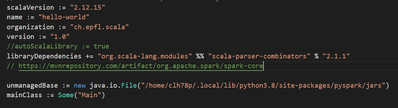
Currently I am learning how to use databricks-connect to develop Scala code using IDE (VS Code) locally. The set-up of the databricks-connect as described here https://docs.microsoft.com/en-us/azure/databricks/dev-tools/databricks-connect was succues...
Is there a way to compare a time stamp within on field/column for an individual ID? For example, if I have two records for an ID and the time stamps are within 5 min of each other....I just want to keep the latest. But, for example, if they were an h...
Since you are trying to do this in SQL, I hope someone else can write you the correct answer. The above example is for pyspark. You can check the SQL synax from Databricks documents