- 1693 Views
- 0 replies
- 0 kudos
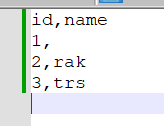
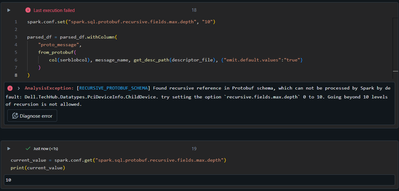
Error during deserializing protobuf data
I am receiving protobuf data in a json attribute and along with it I receive a descriptor file.I am using from_protobuf to deserialize the data as below,It works most of the time but giving error when there are some recursive fields within the protob...
- 1693 Views
- 0 replies
- 0 kudos