I am able to connect to the cluster, browse its hive catalog, see tables/views and columns/datatypesRunning a simple select statement from a view on a parquet file produces this error and no other results:"SQL Error [500540] [HY000]: [Databricks][Dat...
Update. I have tried SQL Workbench/J and encountered exactly the same error(s) as with Dbeaver. I have also tried JetBrains DataGrip and it worked flawlessly. Able to connect, browse the databases and query tables/views. https://docs.microsoft.com/en...
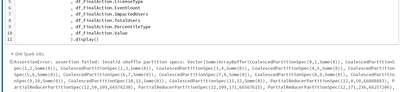
I hv a complex script which consuming more then 100GB data and have some aggregation on it and in the end I am simply try simply write/display data from Data frame. Then i am getting issue (assertion failed: Invalid shuffle partition specs: ).Pls hel...
I am trying to execute a local PySpark script on a Databricks cluster via dbx utility to test how passing arguments to python works in Databricks when developing locally. However, the test arguments I am passing are not being read for some reason. Co...
You can pass parameters using dbx launch --parametersIf you want to define it in the deployment template please try to follow exactly databricks API 2.1 schema https://docs.databricks.com/dev-tools/api/latest/jobs.html#operation/JobsCreate (for examp...
When attempting to deploy/start an Databricks cluster on AWS through the UI, the following error consistently occurs:Bootstrap Timeout:[id: InstanceId(i-093caac78cdbfa7e1), status: INSTANCE_INITIALIZING, workerEnvId:WorkerEnvId(workerenv-335698072713...
Hi @Junaid Ahmed, Nice to meet you, and Thank you for asking me this question. We have had a similar issue in the past and got the best answer too on it.Please see this community thread with the same question. Please let us know if that helps you.
I used python futures to call a function multiple times concurrently, however I am not sure if all nodes is utilised or how to make sure it use all cluster nodes.Can you confirm if I create a cluster with 5 works each with 8 memory cores for example....
Hi I would like to use the azure artifact feed as my default index-url when doing a pip install on a Databricks cluster. I understand I can achieve this by updating the pip.conf file with my artifact feed as the index-url. Does anyone know where i...
for your first question https://docs.databricks.com/libraries/index.html#python-environment-management and https://docs.databricks.com/libraries/notebooks-python-libraries.html#manage-libraries-with-pip-commands this may help. again you can convert t...
Hi guys, I have around 600GB per load, in you opnion, what is the best way to encrypt PII data in terms of performance ? (lib, cluster type, etc.)Thank youWilliam
Hello @William Scardua please check if the blog helps you.https://databricks.com/blog/2020/11/20/enforcing-column-level-encryption-and-avoiding-data-duplication-with-pii.html
@Michael Galli I don't think you can monitor metrics captured by mspnp/spark-monitoring in datadog, there is a service called Azure Log Analytics workspace where these logs are available for querying.You can also check out below if you are interest...
We have the situation where many concurrent Azure Datafactory Notebooks are running in one single Databricks Interactive Cluster (Azure E8 Series Driver, 1-10 E4 Series Drivers autoscaling).Each notebook reads data, does a dataframe.cache(), just to ...
This cache is dynamically saved to disk if there is no place in memory. So I don't see it as an issue. However, the best practice is to use "unpersist()" method in your code after caching. As in the example below, my answer, the cache/persist method ...
i facing the problem here in creating cluster in databricks. Error as below :MessageCluster terminated.Reason:Unexpected launch failureAn unexpected error was encountered while setting up the cluster. Please retry and contact Databricks if the proble...
Hi @Giin Sing Wong ,Just a friendly follow-up. Is this issue still happening or you were able to resolve it by increasing your account's quota? Please let us know.
I am trying to run command to retrieve change data from sql endpoint. It is throwing below error."The input query contains unsupported data source(s).Only csv, json, avro, delta, parquet, orc, text data sources are supported on Databricks SQL."But th...
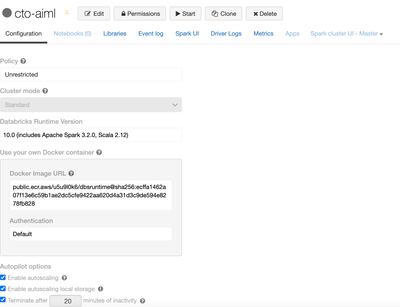
I was trying to start of the Databricks cluster through a docker image. I followed the setup instruction. Excluding the additional setup to setup the IAM role and instance profile as I was facing issues.The image is stored on AWS ECR in a public repo...
Hi @Aman Gaurav , Please check the below requirements to avail the Databricks Container Services.Note :-Databricks Runtime for Machine Learning and Databricks Runtime for Genomics does not support Databricks Container Services.Databricks Runtime 6.1...
I recently posted this in Stack Overflow. I'm using R in Databricks. R Studio runs fine and executes from the Databricks cluster. I would like to transition from R Studio to notebooks. When I start the cluster, R seems to run fine from notebooks. ...
@Paul Evangelista - Thank you for letting us know. You did great!Would you be happy to mark your answer as best so that others can find your solution more easily?
Why does /dbfs seem to be empty in my Databricks cluster ?If I run %sh ls /dbfsI get no output.I am looking for the databricks-datasets subdirectory ? I can't find it under /dbfs
G1GC can solve problems in some cases where garbage collection is a bottleneck. checkout https://databricks.com/blog/2015/05/28/tuning-java-garbage-collection-for-spark-applications.html