I have a workflow which will run every month and it will create a new notebook containing the outputs from the main notebook. However, after some time, the outputs from the created notebook will disappear. Is there anyway I can retain the outputs?
@Shaun Ang :There are a few possible reasons why the outputs from the created notebook might be disappearing:Notebook permissions: It's possible that the user or service account running the workflow does not have permission to write to the destinati...
I am working on Azure databricks(IDE). I wanted to create a button which takes a text value as input and on the click of a button a function needed to be run which prints the value entered.For that I created this code:from IPython.display import disp...
Hi @Shubham Ringne Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us s...
Hello, I have an Databricks account on Azure, and the goal is to compare different image tagging services from Azure, GCP, AWS via corresponding API calls, with Python notebook. I have problems with GCP vision API calls, specifically with credentials...
Ok, here is a trick: in my case, the file with GCP credentials is stored in notebook workspace storage, which is not visible to os.environ() command. So solution is to read a content of this file, and save it to the cluster storage attached to the no...
Hi DataBricks Experts:I'm using Databricks on Azure.... I'd like to understand the following:1) if there is way of automating the re run some specific failed tasks from a job (with several Tasks), for example if I have 4 tasks, and the task 1 and 2 h...
You can use "retries".In Workflow, select your job, the task, and in the options below, configure retries.If so, you can also see more options at:https://learn.microsoft.com/pt-br/azure/databricks/dev-tools/api/2.0/jobs?source=recommendations
I want to use the same spark session which created in one notebook and need to be used in another notebook in across same environment, Example, if some of the (variable)object got initialized in the first notebook, i need to use the same object in t...
Code:Writer.jdbc_writer("Economy",economy,conf=CONF.MSSQL.to_dict(), modified_by=JOB_ID['Economy'])The problem arises when i try to run the code, in the specified databricks notebook, An error of "ValueError: not enough values to unpack (expected 2, ...
@Jillinie Park :The error message you are seeing ("ValueError: not enough values to unpack (expected 2, got 1)") occurs when you try to unpack an iterable object into too few variables. In your case, the error is happening on this line of code:schem...
Hi Friends,I am designing a Testing framework using Databricks and pytest. Currently stuck with report generation, that is generating blank with only default parameters only .for ex :-testsuites><testsuite name="pytest" errors="0" failures="0" skippe...
@Vijaya Palreddy :There are several testing frameworks available for data testing that you can consider using with Databricks and Pytest:Great Expectations: Great Expectations is an open-source framework that provides a simple way to create and main...
I'm trying to create a simple UI for a notebook using the recently implemented support for ipywidgets, but I'm having a hard time figuring out how to change certain style attributes like font size and color in widgets that should accept those style p...
Hey Michael,The example you're trying to run is for ipywidgets 8, we currently have ipywidgets 7-which has fewer button customizations. I believe the only font customization available in 7 is "font_weigh t" (no space). I hope this helps.Best,Miguel
Support of running multiple cells at a time in databricks notebookHi all,Now databricks notebook supports parallel run of commands in a single notebook that will help run ad hoc queries simultaneously without creating a separate notebook.Once you run...
Hi @Ajay Pandey Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so w...
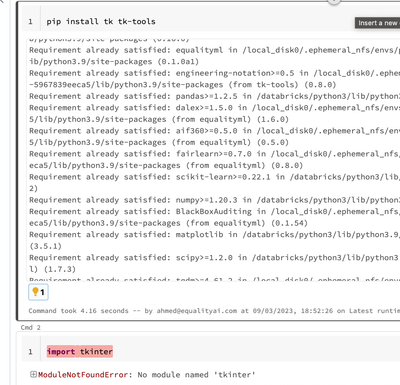
Hello,I'm trying to install a library called aif360 on the databricks notebook. However, I get error that tkinter is not installed.I tried installing tk and tk-tools, but still the issue remains. Any idea on what solution we can use? I also tried ins...
Hi @Ahmed Elghareeb Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.This will ...
I am attempting to save a pandas DataFrame to as csv to a directory I created in Databricks workspace or in the `cwd`. import pandas as pd
import os
df.to_csv("data.csv", index=False)
df.to_csv(str(os.getcwd()) + "/data.csv", index=False)
...
Hi @Keval Shah ,You can save your dataframe to csv in dbfs storage.Please refer below code that might help you-df = pd.read_csv(StringIO(data), sep=',')
#print(df)
df.to_csv('/dbfs/FileStore/ajay/file1.txt')
The databricks notebook failed yesterday due to timestamp format issue. error:"SparkUpgradeException: You may get a different result due to the upgrading of Spark 3.0: Fail to parse '2022-08-10 00:00:14.2760000' in the new parser. You can set spark.s...
You must have solved this issue by now but for the sake of those that encounter this again, here's the solution that worked for me:spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")
Hello everyone, I am trying to setup Databricks CLI by referring to the Databricks CLI documentation. When I setup using the Personal Access Token, it works fine and I am able to access the workspace and fetch the results from the same workspace in D...
Hi @Juned Mala Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!
I am working on Databricks Notebook and trying to display a map using Floium and I keep getting this error > Command result size exceeds limit: Exceeded 20971520 bytes (current = 20973510)How can I get increase the memory limit?I already reduced the...
Hi, I have the same problem with keplergl, and the save to disk option, whilst helpful isn't super practical... So how does one plot large datasets in kepler?Any thought welcome