We are doing DBFS migration. In that we have a folder 'user' in Root DBFS having data 5.8 TB in legacy workspace. We performed AWS CLi Sync/cp between Legacy to Target and again performed the same between Target bucket to Target dbfs While implemen...
Thanks for the quick response.Regarding the suggested AWS data sync approach, we have tried data sync in multiple ways, it is creating folders in s3 bucket itself not on DBFS. As our task is to copy from bucket to DBFS.It seems that it only supports ...
When i run the below query in databricks sql the Precision and scale of the decimal column is getting changed.Select typeof(COALESCE(Cast(3.45 as decimal(15,6)),0));o/p: decimal(16,6)expected o/p: decimal(15,6)Any reason why the Precision and scale i...
Py4JJavaError: An error occurred while calling o236.sql. : org.apache.spark.SparkException: Job aborted. at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:201) at org.apache.spark.sql.execution.datasources.I...
could you please increase the below config (at the cluster level) to a higher value or set it to zero spark.databricks.queryWatchdog.maxQueryTasks 0The spark config while it alleviates the issue.
I have a column that is an array of objects, let's call it ARRAY, and now I would like to query / manipulate, the elements object without using explode function, this is an example, for each element in that column I would like to create a path. .wit...
Hello I am working with Scala, and I used somehing similar:def play(col: Column): Column = { concat_ws("", lit(imagePath), lit("/"), col("field1"), lit("/"), col("field2"), lit(".ext"))}val variable = spark.lot_of_stuff. .withColumn("...
When I'm running TPC-DS (1TB) benchmark on Photon 10.2 and I see the following failures: Queries Q06, Q09 and Q41 fail with the error "Query: AEValueSubQuery is not supported". Q66 fails with the error "[MISSING_COLUMN] org.apache.spark.sql.A...
Hello,I'm learning Scala / Spark and try to understand what's wrong with my function:I have a spark.sql query, stored in a variable:val uViewName = spark.sql("""
SELECT
v.Data_View_Name
FROM
apoHierarchy AS h
INNER JOIN apoView AS v ON h.View_N...
try add .first()(0) it will return only value from first row/column as currently you are returning Dataset: var uViewName = spark.sql(s"""
SELECT
v.Data_View_Name
FROM
apoHierarchy AS h
INNER JOIN apoView AS v ON h.View_Name = v.Context_View_N...
Hi! I have some jobs that stay idle for some time when getting data from a S3 mount on DBFS, this are all SQL queries on Delta, how can I know where is the bottle neck, duration, cue? to diagnose the slow spark performance that I think is on the proc...
We found out we were regeneratig the symlink manifest for all the partitions on this case. And for some reason it was executed twice, at start and end of the job.delta_table.generate('symlink_format_manifest')We configured the table with:ALTER TABLE ...
Is there a way to use sql desktop tools? because delta OSS or databricks does not provide desktop client (similar to azure data studio) to browse and query delta lake objects.I currently use databricks SQL , a webUI in the databricks workspace but se...
DSR is Delta Standalone Reader. see more here - https://docs.delta.io/latest/delta-standalone.htmlIts a crate (and also now a py library) that allows you to connect to delta tables without using spark (e.g. directly from python and not using pyspa...
Hello.I want to know how to do an UPDATE on Azure SQL DataBase from Azure Databricks using PySpark.I know how to make query as SELECT and turn it into DataFrame, but how to send back some data (as UPDATE on rows)?I want to use build in pyspark istead...
This is discussed on Stack Overflow. As you see for Azure Synapse there is a way, but for a plain SQL database you will have to use some kind of driver like odbc/jdbc.
I have installed Databricks-Connect (9.1 LTS). I am able to send queries to the cluster. However, when the query includes a call to the 'table_changes' function that is a part of Change Data Feed, I get the following error:AnalysisException("could ...
Hi @Kaniz Fatma , the table_changes function is an internal Databricks function used in Change Data Feed (CDF).Please refer to the article below. It discusses the table_changes function.https://docs.databricks.com/delta/delta-change-data-feed.html
@somanath Sankaran - Would you be happy to mark @Hubert Dudek's answer as best if it resolved the problem? That helps other members who are searching for answers find the solution more quickly.
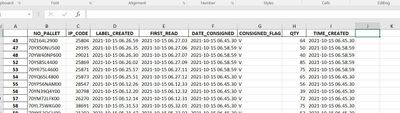
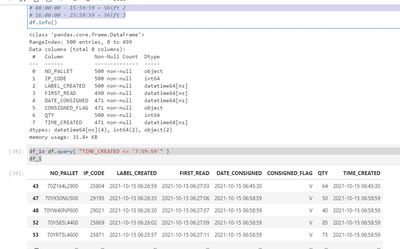
1. I have data x,I would like to create a new column with the condition that the value are 1, 2 or 32. The name of the column is SHIFT where this SHIFT column will be filled automatically if the TIME_CREATED column meets the conditions.3. the conditi...
You an do something like this in pandas. Note there could be a more performant way to do this too. import pandas as pd
import numpy as np
df = pd.DataFrame({'a':[1,2,3,4]})
df.head()
> a
> 0 1
> 1 2
> 2 3
> 3 4
conditions = [(df['a'] <=2...
Hi,I am wondering what documentation exists on Query Pushdown in Snowflake.I noticed that a single function (monitonically_increasing_id()) prevented the entire query being pushed down to Snowflake during an ETL process. Is Pushdown coming from the S...
Hi Sam,The Spark Connector applies predicate and query pushdown by capturing and analyzing the Spark logical plans for SQL operations. When the data source is Snowflake, the operations are translated into a SQL query and then executed in Snowflake to...
If you are using Photon on Databricks SQLClick the Query History icon on the sidebar.Click the line containing the query you’d like to analyze.On the Query Details pop-up, click Execution Details.Look at the Task Time in Photon metric at the bottom.